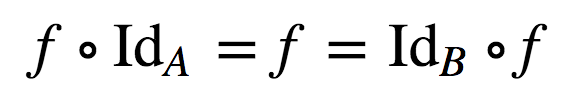
Function composition is the process of applying a function to the
output of another function. In algebra, given two functions,
f and g,
( f ° g )( x ) = f( g( x )). The circle symbol is the
composition operator commonly pronounced “composed with” or “after”. One
can say “f is composed of g” or “f after g” because g is
evaluated first and its output is passed as an argument to
f.
Every time you write code like the following, you’re composing functions:
const g = n => n + 1;
const f = n => n * 2;
const doStuff = x => {
const afterG = g( x );
const afterF = f( afterG );
return afterF;
};
doStuff( 20 ); // 42Every time you write a Promise chain, you’re composing
functions:
const g = n => n + 1;
const f = n => n * 2;
const wait = time => new Promise(
( resolve, reject ) => setTimeout(
resolve,
time
)
);
wait( 300 )
.then(() => 20 )
.then( g )
.then( f )
.then( value => console.log( value )) //42
;Every time you chain array method calls, lodash methods, observables (RxJS, etc…) you’re composing functions. If you’re chaining, you’re composing. If you’re passing return values into other functions, you’re composing. If you call two methods in a sequence, you’re composing using this as input data.
If you’re chaining, you’re composing.
When you compose functions intentionally, you’ll do it better.
Composing functions intentionally, we can improve our
doStuff() function to a simple one-liner:
const g = n => n + 1;
const f = n => n * 2;
const doStuffBetter = x => f( g( x ));
doStuffBetter( 20 ); // 42A common objection to this form is that it’s harder to debug. For example, how would we write this using function composition?
const doStuff = x => {
const afterG = g( x );
console.log( `after g: ${ afterG }` );
const afterF = f( afterG );
console.log( `after f: ${ afterF }` );
return afterF;
};
dostuff( 20 );
/*
"after g: 21"
"after f: 42:
*/Firstly, let’s abstract that “after f” and “after g” logging into a
little utility called trace():
const trace = label => value => {
console.log( `${ label }: ${ value }` );
return value;
};Now we can use it like this:
const doStuff = x => {
const afterG = g( x );
trace( "after g" )( afterG );
const afterF = f( afterG );
trace( "after f" )( afterF );
return afterF;
};
doStuff( 20 );
/*
"after g : 21"
"after f : 42"
*/Popular functional programming libraries like Lodash and Ramda include utilities to make functional composition easier. You can rewrite the above function like this:
import pipe from "lodash/fp/flow";
const doStuffBetter = pipe(
g,
trace( "after g" ),
f,
trace( "after f" )
);
doStuffBetter( 20 );
/*
"after g: 21"
"after f: 42:
*/If you want to try this code without importing anything, you can define pipe like this:
// pipe( ...fns: [ ...Function ]) => x => y
const pipe( ...fns ) => x => fns.reduce(( y, f ) => f( y ), x );Don’t worry if you’re not following how that works, yet. Later on we’ll explore function composition in a lot more detail. In fact, it’s so essential, you’ll see it defined and demonstrated many times throughout this text. The point is to help you become so familiar with it that its definition and usage becomes automatic.
pipe() creates a pipeline of functions, passing the
output of one function to the input of another. When you use
pipe() (and its twin, compose()) you don’t
need intermediary variables. Writing functions without mention of the
arguments is called point-free style. To do it, you’ll
call a function that returns the new function, rather than declaring the
function explicitly. That means you won’t need the function
keyword or the arrow syntax.
Point-free style can be taken too far, but a little bit here and there is great because those intermediary variables add unnecessary complexity to your functions.
There are several benefits to reduced complexity:
The average human brain has only a few shared resources for discrete quanta in working memory, and each variable potentially consumes one of those quanta. As you add more variables, our ability to accurately recall the meaning of each variable is diminished. Working memory models typically involve 4-7 discrete quanta. Above those numbers, error rates dramatically increase.
Using the pipe form, we eliminated 3 variables — freeing up almost half of our available working memory for other things. That reduces our cognitive load significantly. Software developers tend to be better at chunking data into working memory than the average person, but not so much more as to weaken the importance of conservation.
Concise code also improves the signal-to-noise ratio of your code. It’s like listening to a radio — when the radio is not tuned properly to the station, you get a lot of static and interference, and it’s harder to hear the music. When you tune it to the correct station, the noise goes away, and you get a stronger musical signal.
Code is the same way. More concise code expression leads to enhanced comprehension.
These are primitives:
const firstName = "Claude";
const lastName = "Debussy";And this is a composite:
const fullName = {
firstName,
lastName
};Likewise, all Arrays, Sets,
Maps, WeakMaps, TypedArrays etc…
are composite datatypes. Any time you build any non-primitive data
structure, you’re preforming some kind of object composition. Class
inheritance can be used to construct composite objects, but it’s a
restrictive and brittle way to do it.
We’ll use a more general definition of object composition from “Categorical Methods in Computer Science: With Aspects from Topology” (1989):
“Composite objects are formed by putting objects together such that each of the latter is ‘part of’ the former.”
Class inheritance is just one kind of composite object construction. All classes produce composite objects, but not all composite objects are produced by classes or class inheritance. Favouring object inheritance over class-based inheritance means composing objects from small component parts rather than inheriting all properties from an ancestor in a class hierarchy. The latter causes a large variety of well-known problems in object oriented design:
The most common form of object composition is known as mixin composition. It works like ice-cream. You start with an object (like vanilla ice-cream), and then mix in the features you want. Add some nuts, caramel, chocolate swirl, and you wind up with nutty caramel chocolate swirl ice cream.
Building composites with class inheritance:
class Foo{
constuctor(){
this.a = "a";
}
}
class Bar extends Foo{
constructor( options ){
super( options );
this.b = "b";
}
}
const myBar = new Bar(); // { a : "a", b : "b" }Building composites with mixin composition:
const a = { a : "a" };
const b = { b : "b" };
const c = { ...a, ...b }; // { a : "a", b : "b" }We’ll explore other styles of object composition in more depth later. For now, your understanding should be:
This isn’t about functional programming (FP) vs object-oriented programming (OOP), or one language vs another. Components can take the form of functions, data structures, classes, etc… Different programming languages tend to afford different atomic elements for components. Java affords classes, Haskel affords functions, etc… But no matter what language and what paradigm you favour, you can’t get away from composing functions and data structures. In the end, that’s what it all boils down to.
No matter how you write software, you should compose it well. The essence of software development is composition.
In the beginning, before most of computer science was actually done on computers, there were two great computer scientists: Alonzo Church and Alan Turing. They produced two different but equivalent universal models of computation.
Alonzo Church invented lambda calculus which is a universal model based on function application. Alan Turing is known for the turing machine. This is a model of computation that defines a theoretical device that manipulates symbols on a strip of tape.
Together they collaborated to demonstrate that the two models were functionally equivalent.
Lambda calculus is all about function composition. Let’s discuss the importance of composition in software design. There are three important points that make lambda calculus special:
const sum = ( x, y ) => x + y is the
anonymous function expression
( x, y ) => x + y.( x, y ) => x + y can be
expressed as a unary function like: x => y => x + y.
This transformation is known as currying.Together, these features form a simple, yet expressive vocabulary for composing software using functions as the primary building block. In javascript, anonymous and curried functions are optional features. While javascript supports important features of lambda calculus, it does not enforce them.
The classic function composition takes the output from one function
and uses it as the input for another function. For example, the
composition f . g can be written as
compose2 = f => g => x => f( g( x )). Here’s how
you’d use it:
double = n => n * 2;
inc = n => n + 1;
compose2( double )( inc )( 3 );The compose2() function takes the double
function as the first argument, the inc function as the
second, and then applies the composition of those two functions to the
argument 3. Looking at the signature of
compose2() again, f is double(),
g is inc() and x is
3. The function call,
compose2( double )( inc )( 3 ), is actually 3 different
function invocations:
double and returns a new
function.inc and returns a new
function.3 and evaluates
f( g( x )), which is now
double( inc (3 )).x evaluates to 3 and gets passes into
inc().inc( 3 ) evaluates to 4.double( 4 ) evaluates to 8.8 gets returned from the function.When software is composed, it can be represented by a graph of function compositions. Consider the following:
append = s1 => s2 => s1 + s2;
append( "Hello, " )( "world!" );You could represent it visually :
___append___
/ \
s1 s2
/ \
"Hello, " "world!"
\ /
\ /
"Hello, world!"Lambda calculus was hugely influential on software design and prior to about 1980 many very influential icons of computer science were building software using its methods. Lisp was created in 1958 based on ideas of lambda calculus. Today, Lisp is the second-oldest language that’s still in popular use. Lisp is a popular teaching language in computer science curriculum for three reasons:
Somewhere between 1970 and 1980, the way that software was created
drifted away from simple compositions, and became a list of linear
instructions for the computer to follow. Then came object-oriented
programming — a great idea about component encapsulation and message
passing that got distorted by popular languages into a horrible idea
about inheritance hierarchies and is-a relationships for
feature reuse.
Functional programming was relegated to the sidelines and academia: The blissful obsession of the geekiest of programming geeks, professors in their ivy league towers, and some lucky students who escaped the Java force-feeding obsession of the 1990’s — 2010’s.
Around 2010 javascript exploded and javascript had important features of lambda calculus. People began to explore a thing called “functional programming”. By 2015, the idea of building software with function composition was popular again. The underlying foundation of javascript (ecmascript) gained new features and added arrow functions. This feature allowed programmers the ability to read and write functions, currying and lambda expressions in a simpler manner.
Composition is a simple, elegant and expressive way to clearly model the behavior of software. The process of composing small, deterministic functions produces software that is easier to organize, understand, debug, extend, test and maintain.
The long story cut short; we are going to use javascript to learn functional programming and composition. We will treat you the programmer, seasoned or beginner, as one and the same starting from the very beginning. Set aside preconceptions and dive in.
Instead of using languages that are more commonly associated with function paradigms, like Haskell, ClojureScript or Elm, we will use javascript. Why? Javascript has the most important features needed for functional programming:
x => x * 2 is a valid function expression in
javascript. Concise lambdas make it easier to work with
higher-order functions.add( 1 )( 2 ), 1 is a fixed
argument in the function returned by add2( 1 ).Javascript is a multi-paradigm language. Other styles supported include procedural (imperitive) programming like C, object-oriented programming and of course function programming. The disadvantage of this approach is that imperative and object-oriented styles tend to imply that almost everything needs to be mutable. Mutation is a change to data structure that happens in-place. For example:
const foo = { bar : "baz" };
foo.bar = "qux"; // mutation - changing the property Objects need to be mutable so that their properties can be updated by methods. Here are some features that some functional languages have that javascript does not:
for, while or do loops.In javascript, purity must be achieved by convention. If you’re not building most of your application by composing pure functions, you’re not programming using the functional style. It’s unfortunately easy in javascript to get off track by accidentally creating and using impure functions.
In pure functional languages, immutability is often enforced. Javascript lacks efficient, immutable trie-based data structures used by most functional languages. There are, however, libraries that help such as Immutable.js and Mori.
ES6 introduced the const keyword that
once invoked cannot be reassigned afterwards to refer to a different
value after. It’s important to understand that const does
not represent an immutable value.
A const object can’t be reassigned to refer to a
completely different object but object properties can be mutated after
invocation. Javascript also has the ability to
freeze() objects but are only frozen at the root level.
This means that a nested object can still have properties of its
properties mutated.
Whilst javascript does feature recursion it does not have a fully developed feature called tail call optimisation. This feature allows functions to reuse stack frames for recursive calls. Without this feature any large recursive iteration can have it’s call stack grow without bounds and cause a stack overflow (not just a website name). Ultimately it isn’t safe to use recursion in javascript for large iterations until tail call optimisation is implemented by all major browser vendors.
Side-effects and mutation may be perceived as a flaw in javascript but it’s nigh-on impossible to create a meaningful application without side-effects. Pure functional languages like Haskel mask side-effects using boxes called monads allowing the program to remain pure even though the side-effects represented by the monads are impure.
The largest hurdle to monads is simply explaining what such a thing is and is often difficult to convey the whys and wherefores.
“A monad is a monoid in the category of endofunctors, what’s the problem?” ~ James Iry, fictionally quoting Philip Wadler, paraphrasing a real quote by Saunders Mac Lane. “A Brief, Incomplete, and Mostly Wrong History of Programming Languages”
As with most things in functional programming the impenetrable academic vocabulary is much harder to understand than the concepts.
The rest of this section is just waffle…
A basic introduction to functional programming with javascript. The best way to use these examples is to follow along using the environment of your choice.
An expression is a chunk of code that evaluates to a value. The following are all valid expressions in javascript:
7 + 1; // 8
7 * 2; // 14
"hello"; // HelloThe value of an expression can be given a name. When you do so, the
expression is evaluated first and the resulting value is assigned to the
name. You can assign the value to var, let or
const.
const hello = "hello";
hello; // "hello"var, let and
constJavascript supports three types of variables:
var, let and const. They can be
thought of in terms of order of selection. By default, one selects the
strictest declaration: const. A variable assigned to a
const cannot be reassigned. The final value must be
assigned at declaration time.
Sometimes it is useful to reassign variables. You may have a looping
structure that needs to increment a variable during each loop. Enter the
let variable. This type of variable is scoped to the code
block (between curly braces) and can be modified.
var tells you the least about the variable as it is the
weakest signal. This text will use const in order to get
you in to the habit of defaulting to const for actual
programs.
Javascript has several types including the two we’ve
seen thus far, numbers and strings, as well as
booleans, arrays, objects and
more.
An array is an ordered list of values. It is a container
that can hold many items or varying types and unlike other languages
javascript doesn’t require you to specify the
size/length of the array at declaration.
[ 1, 2, 3 ]; // array literal notation
const arr = [ 1, 2, 3 ]; // assigned to const named arrAn object in javascript is a collection of
key: value pairs.
{ key : "value" }; // literal notation
const foo = { bar : "bar" }; // assigned to const named fooIf you want to assign existing variables to object property keys of the same name there’s a shortcut for that. You can just type the variable name instead of providing both a key and a value:
const a = "a";
const oldA = { a : a }; // long, redundant way
const oA = { a }; // short and sweet!
/* Just for posterity, let's do that again */
const b = "b";
const oB = { b };Objects can be easily composed together into new
objects:
const c = { ...oA, ...oB }; // { a : "a", b : "b" }Those three dots are the object spread operator. It iterates
over the properties in oA and assigns them to the new
object then does the same for oB. Any keys that already
exist in on the new object will be overwritten. The object spread
operator is quite well supported at this time but in the event that you
must support a browser that doesn’t utilise it you can substitute with
Object.assign():
const d = Object.assign({}, oA, oB ); // { a : "a", b : "b" }The first argument to Object.assign() is the destination
of the assignment. In the example above that will be an
object. When leaving out the destination argument, the
first object passed will be mutated with the subsequent arguments. Bear
this in mind.
Both objects and arrays support
destructuring allowing you to extract values from them and assign to
named variables:
const [ t, u ] = [ "a", "b" ];
t; // "a"
u; // "b"
const blep = { blop : "blop" };
// the following is equivalent to:
// const blop = blep.blop;
const { blop } = blep;
blop; // "blop"As with the array example above, you can destructure to
multiple assignments at once. Here’s a line you’ll see in many
Redux projects: const { type, payload } = action;
This is how the proceeding line is used the context of a reducer
(more on this later):
const myReducer = ( state = {}, action = {}) => {
const ( type, payload ) = action;
switch( type ){
case "FOO" : return Object.assign({}, state, payload );
default : return state;
}
};If you don’t want to use a different name for the new binding you can assign a new name:
const { blop : bloop } = blep;
bloop; // "blop"
// read: assign blep.blop as bloopEd. The above line is a touch confusing. Why not
simply use bloop as the const name? Hopefully
this usage will become more clear later on.
There are two ways to compare two values: using the “double equals”
operator, ==, or the strict equality operator
===. The former uses type coercion behind the scenes to
allow you to compare values of different type
e.g. true == 1. The strict equality operator, or “triple
equals”, must be used between values of the same type
e.g. true === true.
Other comparison operators include:
> Greater than< Less than>= Greater than or equal to<= Less than or equal to!= Not equal!== Not strict equal&& Logical and|| Logical orA ternary expression is a boolean expression that evaluates to true
or false. Only one branch of the ternary will be executed based on the
question asked (using a compactor):
14 - 7 === 7 ? "Yep!" : "Nope."; // Yep!.
Javascript has function expressions that can be
assigned to names: const doubles = x => x * 2;. This
means the same thing as the mathematical function
f( x ) = 2x. Spoken aloud, the function reads as
f of x equals 2x To use the
function one simply calls it with a value like so: f( 2 )
which will evaluate to 4.
In other words, f( 2 ) = 4. You can think of a math
function as a mapping from inputs to outputs. f( x ) in
this case is a mapping of input values for x to
corresponding output values equal to the product of the input value and
2. In javascript the value of a function
expression is the function itself:
double; // [Function: double ]. You can see the function
definition using the .toString() method:
double.toString(); // "x => x * 2".
Functions have signatures which consist of:
Type signatures do not need to be specified in javascript and are figured out by the javascript engine at runtime. Javascript lacks its own function signature notation so there are a few competing standards. JSDoc has been very popular historically but it’s awkwardly verbose and few manage to keep the comments up-to-date along with the code.TypeScript and Flow are currently big contenders and then theres RType for documentation purposes only. Perhaps this is a lacking field chiefly because good documentation is hard whilst being a largely boring task. The two go hand in hand resulting in developers not going hand in hand with documentation.
The signature for doubles is:
double( x : n ) => n.
In spite of the fact that javascript doesn’t require signatures to be annotated, knowing what signatures are and what they mean will still be important in order to communicate efficiently about how functions are used and how functions are composed. Most reusable function composition utilities require you to pass functions which share the same type signature.
Javascript supports default parameters values. The
following function works like an identity function (a function which
returns the same value you pass in) unless you call it with
undefined or simply pass no argument at all:
const orZero = ( n = 0 ) => n.
To set a default one simply assigns it to the parameter with the
= operator in the function signature. When assigned in this
fashion, type inference tools such as Tern.js,
Flow or TypeScript can infer the type
signature of your function automatically even if you don’t explicitly
declare type annotations.
The result is that, with the right plugins installed in your editor or IDE, you’ll be able to see function signatures displayed inline as you’re typing function calls. You’ll also be able to understand how to use a function at a glance based on its call signature. Using default assignments wherever it makes sense can help you write more self-documenting code.
Note: Parameters with defaults don’t count toward the functions
.lengthproperty which will throw off utilities such as autocurry which depend on the.lengthvalue. Some curry utilities (such as lodash/curry) allow you to pass a custom arity to work around this limitation if you bump into it.
Javascript functions can take object literals as arguments and use destructuring assignment in the parameter signature in order to achieve the equivalent of named arguments. Notice, you can also assign default values to parameters using the default parameters feature:
const createUser = ({
name = "Anonymous",
avatarThumbnail = "/avatars/anonymous.png"
}) => ({
name,
avatarThumbnail
});
const george = createUser({
name : "George",
avatarThumbnail : "avatars/shades-emoji.png"
});
george;
/*
{
name : "George",
avatarThumbnail : "avatars/shades-emoji.png"
}
*/A common feature of functions in javascript is the
ability to gather together a group of remaining arguments in the
functions signature using the rest operator: .... The
following function simply discards the first argument and returns the
rest as an array:
const aTail = ( head, ...tail ) => tail;
aTail( 1, 2, 3 ); // [ 2, 3 ]Rest gathers individual elements together into an
array. Spread does the opposite: it spreads
the elements from an array to individual elements. Consider
this:
const shiftToLast = ( head, ...tail ) => [ ...tail, head ];
shiftToLast( 1, 2, 3 ); // [ 2, 3, 1 ]Arrays in javascript have an iterator
that gets invoked when the spread operator is used. For each item in the
array, the iterator delivers a value. In the expression,
[ ...tail, head ], the iterator copies each element in
order from the tail array into the new
array created by the surrounding literal notation. Since
the head is already an individual element, we just plop it
onto the end of the array and we’re done.
Curry and partial application can be enabled by returning another function:
const highpass = cutoff => n => n >= cutoff;
const gt4 = highpass( 4 ); // highpass() returns a new function
// using the function keyword rather than arrow functions
const highpass = function highpass( cutoff ){
return function( n ){
return n >= cutoff;
};
};The arrow in javascript roughly means “function”.
There are some important differences in function behaviour depending on
which kind of function you use (=> lacks its own
this, and can’t be used as a constructor). When you see
x => x think a “a function that take x and
returns x. So you can read
const highpass = cutoff => n => N >= cutoff;
as:
“highpass is a function which takes cutoff
and returns a function which takes n and returns the result
of n >= cutoff”.
Since highpass() returns a function you can use it to
create a more specialized function:
const gt4 = highpass( 4 );
gt4( 6 ); // true
gt4( 3 ); // falseAutocurry lets you curry functions automatically for maximal
flexibility. Presume you have a function add3():
const add3 = curry(( a, b, c ) => a + b + c );. With
autocurry you can use it in several different ways and it will
return the right thing depending on how many arguments you pass in:
add3( 1, 2, 3 ); // 6
add3( 1, 2 )( 3 ); // 6
add3( 1 )( 2, 3 ); // 6
add3( 1 )( 2 )( 3 ); // 6Whilst javascript lacks a built-in
autocurry mechanism you can import one from
Lodash: $ yarn add lodash. This will be
ready for use with the following command:
import curry form "lodash/curry";. Should you prefer to
write your own autocurry function try this on for size:
const curry = (
f, arr = []
) => ( ...args ) => (
a => a.length === f.length ?
f( ...a ) :
curry( f, a )
)([ ...arr, ...args ]);In mathematical notation functional composition is:
f . g. This is the process of passing a return value on one
function to another as an argument. The javascript
equivalent is: f( g( x )). It is evaluated from the inside
out:
x is evaluated.g() is applied to x.f() is applied to the return value of
g( x ).For example:
const inc = n => n + 1;
inc( double ( 2 )); // 5The value 2 is applied to double() and the
result, or return value, is applied to inc(). The last
function that runs will be inc( 4 ) // 5. Any expression
can be passed as an argument to a function and will be evaluated before
being applied to the function:
inc( double( 2 ) * double( 2 )); // 17. In this example the
two double() functions are evaluated returning
4 * 4 that is then applied to inc().
Function composition is central to functional programming and shall explore this topic in greater detail later on.
Arrays have some built-in methods. A method is a
function associated with an object and is usually a property of the
associated object:
const arr = [ 1, 2, 3 ];
arr.map( double ); // [ 2, 4, 6 ];In this case, arr is the object,
.map() is a property of the object with a function for a
value. When invoked, the function gets applied to the arguments as well
as a special parameter called this which gets automatically
set when the method is invoked. Note that we’re passing the
double function as a value into map rather
than calling it. That’s because map takes a function as an
argument and applies it to each item in the array. It
returns a new array containing the values returned by
double(). In creating and returning a new
array, the original arr is left untouched and
not mutated.
Method chaining is the process of directly calling a method on the return value of a function without needing to refer to the return value by name:
const arr = [ 1, 2, 3 ];
arr.map( double ).map( double ); // [ 4, 8, 12 ]A predicate is the function that returns a
boolean value. The .filter() method takes a
predicate and returns a new list selecting only the items that pass the
predicate to be included in the new list:
[ 2, 4, 6 ].filter( gt4 ); // [ 4, 6 ]. Frequently you’ll
want to filter a list then map those items to a new list:
[ 2, 4, 6 ].filter( gt4 ).map( double ); // [ 8, 12 ].
…and that’s our overview of functional javascript. A bit of a whirlwind and not exhaustive by any means. Later on we’ll develop these ideas in examples. Onwards…
A higher order function is a function that takes a function
as an argument or returns a function. Higher order function is in
contrast to first order functions which don’t take a function as an
argument or return a function as output. Earlier we saw examples of
.map() and .filter(). Both of them take a
function as an argument meaning, yes, they are both higher order
functions. Let’s look at an example of a first-order function that
filters all the 4-letter words from a list of words:
const censor = words => {
const filtered = [];
for( let i = 0, { length } = words, i < length; i++ ){
const word = words[ i ];
if( word.length !== 4 ) filtered.push( word );
}
return filtered;
};
censor([ "oops", "gasp", "shout", "sun" ]);
// [ "shout", "sun" ]Now should we want to select all the words that begin with “s”? We could create another function:
const startsWithS = words => {
const filtered = [];
for( let i = 0, { length } = words; i < length; i++ ){
const word = words[ i ];
if( word[ 0 ] == "s" || word[ 0 ] == "S" ) filtered.push( word );
}
return filtered;
}
startsWithS([ "oops", "gasp", "shout", "sun" ]);
// [ "shout", "sun" ]In just two functions we’ve begun to repeat ourselves. The two functions are very specific and aren’t very portable. We can abstract the iteration and filtering to build all sorts of similar functions. Luckily for us, javascript has first class functions. What does that mean?
In essence, we can use functions just like any other bits of data in our programs making abstraction a lot easier. For instance, we can create a function that abstracts the process of iterating over a list an accumulating a return value by passing in a function that handles the bits that are different. We’ll call that function the reducer:
const reduce = ( reducer, initial, arr ) => {
// shared stuff
let acc = initial;
for( let i = 0, length = arr.length; i < length; i++ ){
// unique stuff in reducer() call
acc = reducer( acc, arr[ i ]);
// more shared stuff
}
return acc;
};
reduce(( acc, curr ) => acc + curr, 0, [ 1, 2, 3 ]); // 6This reduce() implementation takes a reducer function,
an initial value for the accumulator and an array of data
to iterate over. For each item in the array the reducer is
called passing it the accumulator and the current array
element. The return value is assigned to the accumulator. When it’s
finished applying the reducer to all of the values in the list the
accumulated value is returned.
In the usage example, we call reduce and pass to it a function,
( acc, curr ) => acc + curr, which takes the accumulator
and the current value in the list and returns a new accumulated value.
Next we pass an initial value, 0 and finally the data to
iterate over. With the iteration and value accumulation abstracted we
can now implement a more generalized filter() function:
const filter = (
fn, arr
) => reduce(( acc, curr ) => fn( curr ) ?
acc.concat([ curr ]) :
acc, [], arr
);In the filter() function everything is shared except the
fn() argument that gets passed. That fn()
argument is called a predicate meaning that it will evaluate to
either true or false. We call
fn() with the current value and if the
fn( curr ) call return true we then concat the
curr value to the accumulator array. Otherwise
we just return the current accumulator value. Noe we can implement
censor() with filter() to filter out 4-letter
words:
const censor = words => filter(
word => word.length !== 4,
words
);Look how much smaller it is! And so is
startsWithS():
const startsWithS - words => filter(
word => word.startsWith( "s" ),
words
);Hold your horse. These reduce() and
filter() functions look awfully familiar. Indeed they are
methods of Array and are rather handy.
Higher order functions are also commonly used to abstract how to
operate on different data types. For instance, .filter()
doesn’t have to operate on arrays of strings.
It could just as easily filter numbers because you can pass
in a function that knows how to deal with a different data type.
Remember highpass()?
cosnt highpass = cutoff => n => n >= cuttoff;
const gt3 = highpass( 3 );
[ 1, 2, 3, 4 ].filter( gt3 ); // [ 3, 4 ]You can use higher order functions to make a function polymorphic. As you can see, higher order functions can be a whole lot more reusable and versatile than their first order cousins. Generally speaking you’ll use higher order functions in combination with very simple first order functions in your real application code.
Reduce (aka: fold, accumulate) utility commonly used in functional programming that lets you iterate over a list applying a function to an accumulated value and the next item in the list until the iteration is complete and the accumulated value gets returned. Many useful things can be implemented with reduce. Frequently it’s the most elegant way to do any non-trivial processing on a collection of items.
Reduce takes a reducer function and an initial value and then returns
the accumulated value. For Array.prototype.reduce() the
initial list is provided by this so it’s not one of the
arguments:
array.reduce(
reducer : ( accumulator: Any, current : Any ) => Any,
initialValue : Any
) => accumulator : AnySum of an array:
[ 2, 4, 6 ].reduce(( acc, n ) => acc + n, 0 ); // 12.
For each element in the array the reducer is called and
passed the accumulator and the current value. The reducer’s job is to
“fold” the current value into the accumulated value somehow. How is not
specified and specifying how is the purpose of the reducer function.The
reducer returns the new accumulated value and recue() moves
on to the next value in the array. The reducer may need an
initial value to start with so most implementations take an initial
value as a parameter.
In the case of this summing reducer the first time the reducer is
called, acc starts at 0 (the value we passed
to .reduce() as the second parameter). The reducer return
0 + 2 with 2 being the first element in the
array. The next call will then return 2 + 4
using the accumulator and next element respectively. This will continue
until there are no more elements and the final accumulation is returned.
The example above uses an anonymous function to serve as the reducer but
we can abstract it and give it a name:
const summingReducer = ( acc, n ) => acc + n;
[ 2, 4, 6 ].reduce( summingReducer, 0 ); // 12Normally, reduce() works from left to right. In
javascript we also have [].reduceRight()
which works in the opposite direction. Of course the previous example
would result in the same total but the first value added to the
accumulator would be 6 rather than 2.
It’s easy to define map(), filter(),
forEach() and lots of other interesting things using
reduce:
const map = ( fn, arr ) => arr.reduce(( acc, item, index, arr ) => {
return acc.concat( fn( item, index, acc ));
}, []);For map, the accumulated value is an array with any element that
satisfies the function passed in (fn );
const filter = ( fn, arr ) => arr.reduce(( newArr, item ) => {
return fn( item ) ? newArr.concat([ item ]) : newArr;
}, []);Filter works in a similar manner as map except that we take a
predicate function and conditionally append the current value
to the new array if the element evaluates to cierto.
For each of the above examples you have a list of data, iterate over that data applying some function and folding the results into an accumulated value. Lots of applications spring to mind. But what if your data is a list of functions?
Reduce is also a convenient way to compose functions. Remember
function composition: if you want to apply the function f
to the result of g of x i.e. the composition,
f . g, you could use the following
javascript: f( g( x ));
Reduce lets us abstract that process to work on any number of
functions so you could easily define a function that would represent:
f( g( h( x ))).
To make that happen we’ll need to run reduce in reverse. That is,
right-to-left. Thankfully javascript provides the means
to do that:
const compose = ( ...fns ) => x => fns.reduceRight(( v, f ) => f( v ), x );.
Note: If javascript had not provided
[].reduceRight()you could still implementreduceRight()– usingreduce(). I’ll leave it to adventurous readers to figure it out how.
compose() is great if you want to represent the
composition form the inside-out – that is, in the math notional sense.
But what if you want to think of it as a sequence of events? Imagine we
want to add 1 to a number and then double it. With
compose() that would be:
const add1 = n => n + 1;
const double = n => n * 2;
const add1ThenDouble = compose(
double,
add1
);
add1ThenDouble( 2 ); // 6
// (( 2 + 1 = 3 ) * 2 = 6 )See the problem? The first step is listed last so in order to
understand the sequence you’ll need to start at the bottom of the list
and work your way backwards to the top. Or we can reduce left-to-right
as you normally would instead of right-to-left:
const pipe = ( ...fns ) => x => fns.reduce(( v, f ) => f( v ), x );.
Now you can write add1ThenDouble() like this:
const add1ThenDouble = pipe(
add1,
double
);
add1ThenDouble( 2 ); // 6
// (( 2 + 1 = 3 ) * 2 = 6 )We’ll go into more detail on compose() and
pipe() later. What you should understand right now is that
reduce() is a very powerful tool and you really need to
learn it. Just be aware that if you get very tricky with reduce some
people have a hard time following along.
A functor data type is something you can map over.
It’s a container which has an interface which can be used to apply a
function to the values inside it. When you see a functor you should
think “mappable”. Functor types are typically represented as an
object with a .map() method that maps from inputs to
outputs while preserving structure. In practice, “preserving structure”
means that the return value is the same type of functor (though values
inside the container may be a different type).
A functor supplies a box with zero or more things inside and a
mapping interface. An array is a good example of a functor
but many other kinds of objects can be mapped over as well such as
promises, streams, trees,
objects etc… Javascript has built in
array and promise objects act like functors.
For collections (arrays, streams, etc…),
.map() typically iterates over the collection and applies
the given function to each value in the collection but not all functors
iterate. Functors are really about applying a function in a specific
context.
Promises use the name .then() instead of
.map(). You can usually think of .then() as an
asynchronous .map() method except when you have a nested
promise in which case it automatically unwraps the outer
promise. Again, for values which are not
promises, .then() acts like an asynchronous
.map(). For values that are promises
themselves .then() acts like the .chain()
method from monads (sometimes also called .bind() or
.flatMap()). So, promises are not quite
functors and not quite monads but in practice you can usually treat them
as either. Don’t worry about what monads are, yet. Monads are a kind of
functor os you need to learn functors first. Lot’s of libraries exist
that will turn a variety of other things into functors too.
In Haskel, the functor type is defined as:
fmap :: ( a -> b ) f a -> f b.
Given a function that takes an a and returns a
b and a functor with zero or more a inside it:
fmap returns a box with zero or more b inside
it. The f a and f b bits can be read a “a
functor of a” and “a functor of b” meaning
f a has a indie the box and f b
has b inside the box.
Using a functor is easy - just call map():
const f = [ 1, 2, 3 ];
f.map( double ); // [ 2, 4, 6 ]Categories have two important properties:
Since a functor is a mapping between categories, functors must respect identity and composition. Together they’re known as the functor laws.
If you pass the identity function (x => x) into
f.map(), where f is the functor, the result
should be equivalent to f:
const f = [ 1, 2, 3 ];
f.map( x => x ); // [ 1, 2, 3 ]Functors must obey the composition law:
F.map( x => f( g ( x )) is equivalent to
F.map( g ).map( f ).
Function Composition is the application of one function to the result
of another e.g. given an x and the functions,
f and g, the composition
( f ° g )( x ) means f( g ( x )).
A lot of functional programming terms come from category theory and the essence of category theory is composition. Category theory is scary at first but easy. Like jumping off a diving board or riding a roller coaster. Here’s the foundation of category theory in a few bullet points:
a -> b -> c
there must be a composition which goes directly from
a -> c.Say you have a function g that takes an a
and returns a b and another function f that
takes a b and returns a c; there must also be
a function h that represents the composition of
f and g. So, the composition from
a -> c is the composition
f ° g (f after g). Hence,
h( x ) = f( g ( x )). Function composition works right to
left, not left to right, which is why f ° g is frequently
called f after g.
Composition is associative. Basically that means that when you’re
composing multiple functions (morphisms if you’re feeling fancy) you
don’t need parenthesis:
h ° ( g ° f ) = ( h ° g ) ° f = h ° g ° f.
Let’s take another look at the composition law in
javascript. Given a functor, F:
const F = [ 1, 2, 3 ];. The following are equivalent:
F.map( x => f( g ( x )));,
F.map( g ).map( f );.
An endofunctor is a functor that maps from a category back to the
same category. A functor can map from category to category:
X -> Y. An endofunctor maps from a category to the same
category: X -> X. A monad is an endofunctor.
Remember:
“A monad is just a monoid in the category of endofunctors. What’s the problem?”
Hopefully that quote is tarting to make a little more sense. We’ll get to monoids and monads later.
Here’s a simple example of a functor:
const Identity = value => ({
map : fn => Identity( fn( value ))
});As you can see, it satisfies the functor laws:
// trace() is a utility to let you easily inspect the content
const trace = x => {
console.log( x );
return x;
};
const u = Identity( 2 );
// Identity law
u.map( trace ); // 2
u.map( x => x ).map( trace ); // 2
const f = n => n + 1;
const = n => n * 2;
// Composition law
const r1 = u.map( x => f( g( x )));
const r2 = u.map( g ).map( f );
r1.map( trace ); // 5
r2.map( trace ); // 5Now you can map over any data type just like you can map over an
array. Nice! That’s about as simple as a functor can get in
javascript but it’s missing some features we expect
from data types in javascript. Let’s add them. Wouldn’t
it be cool if the + operator could work for number and
string values?
To make that work all we need to do is implement
.valueOf() which also seems like a convenient way to unwrap
the value from the functor:
const Identity = value => ({
map : fn => Identity( fn( value )),
valueOf : () => value
});
const ints = ( Identity( 2 ) + Identity( 4 ));
trace( ints ); // 6
const hi = ( Identity( "h" ) + Identity( "i" ));
trace( hi ); // "hi"Super. But what if we want to inspect an Identity
instance in the console? It would be cool if it would say
Identity( value ). Let’s add a .toString()
method: toString: () => `Identity( ${ value }).
We should probably also enable the standard JS iteration protocol. We can do that by adding a custom iterator:
[ Symbol.iterator ]: () => {
let first = true;
return ({
next : () => {
if( first ){
first = false;
return ({
done : false,
value
});
}
return ({
done : true
});
}
});
}Now this will work:
// [ Symbol.iterator ] enables standard JS iterations:
const arr = [ 6, 7, ...Identity( 8 )];
trace( arr ); // [ 6, 7, 8 ]What if one wants to take an Identity( n ) and return an
array of Identities containing n + 1, n + 2
and so on? Easy right?
const fRange = ( start, end ) => Array.from(
{ length : end - start + 1 },
( x, i ) => Identity( i + start )
);How do we make this work with any functor? What if we had a spec that said that each instance of a data type must have a reference to its constructor? Then you could do this:
const fRange = (
start, end
) => Array.from(
{ length : end - start + 1 },
// change `Identity` to `start.constructor`
( x, i ) => start.constructor( i + start )
);
const range = fRange( Identity( 2 ), 4 );
range.map( x => x.map( trace )); // 2, 3, 4To test if the value is a functor we could add a static method on
Identity to check. We should throw in a static
.toString() where we’re at it:
Object.assign( Identity, {
toString : () => "Identity",
is : x => typeof x.map === "function"
});Now the whole kit and caboodle:
const Identity = value => ({
map : fn => Identity( fn( value )),
valueOf : () => value,
toString : () => `Identity( ${ value })`,
[ Symbol.iterator ] : () => {
let first = true;
return ({
next : () => {
if( first ){
first = false;
return ({
done : false,
value
});
}
return ({
done : true
});
}
});
},
constructor : Identity
});
Object.assign( Identity, {
toString : () => "Identity",
is : x => typeof x.map === "function"
});Note you don’t need all this extra stuff for something to qualify as
a functor or an endofunctor. It’s strictly for convenience. All you need
for a functor is a .map() interface that staidfies the
functor laws.
Functors are great for lots of reasons. Most importantly, they’re an
abstraction that you can use to implement lots of useful things in a way
that works with any data type. For instance, what if you want to kick
off a chain of operations but only if the value inside the functor is
not undefined or null?
// Create the predicate
const exists = x => ( x.valueOf() !== undefined && x.valueOf !== null );
const ifExists = x => ({
map : fn => exists( x ) ? x.map( fn ) : x
});
const add1 = n => n + 1;
const double = n => n * 2;
// Nothing happens…
ifExists( Identity( undefined )).map( trace );
// Still nothing happens…
ifExists( Identity( null )).map( trace );
// 42
ifExists( Identity( 20 ))
.map( add1 )
.map( double )
.map( trace )
;Of course, functional programming is all about composing tiny functions to create higher level abstractions. What if you want a generic map that works with an y functor? That way you can partially apply arguments to create new functions. Easy. Pick your favourite auto-curry or use this magic spell from before:
const curry = (
f, arr = []
) => ( ..args ) => (
a => a.length === f.length ?
f( ...a ) :
curry( f, a )
)([ ...arr, ...args ]);Now we can customise map:
const map = curry(( fn, F ) => F.map( fn ));
const double = n => n * 2;
const mdouble = map( double );
mdouble( Identity( 4 )).map( trace ); // 8Functors are things we can map over. More specifically a functor is a mapping from category to category. A functor can even map from a category back to the same category (i.e. an endofucntion).
A category is a collection of objects with arrows between objects.
Arrows represent morphisms (aka functions, aka compositions). Each
object in a category has an identity morphism (x => x).
For any chain of objects A -> B -> C there must exist
a composition A -> C.
Functors are great higher-order abstractions that allow you to create a variety of generic functions that will work for any data type.
Functional mixins are composable factory function which connect together in a pipeline; each function adding some properties or behaviours like workers on an assembly line. Functional mixins don’t depend on or require a base factory or constructor: simply pass any arbitrary object into a mixin and an enhanced version of that object will be returned.
Functional mixins features:
All modern software development is really composition: we break a large, complex problem down into smaller, simpler problems, and then compose solutions to form an application.
The atomic units of composition are on of two things:
Application structure is defined by the composition of those atomic
units. Often, composite objects are produced using class inheritance,
where a class inherits the bulk of its functionality forma parent class,
and extends or overrides pieces. The problem with that approach is that
it leads to is-a thinking, e.g. “an admin is an employee”,
causing lots of design problems:
If an admin is an employee, how do you handle a situation where you hire an outside consultant to perform administrative duties temporarily? If you knew every requirement in advance, perhaps class inheritance could work, but I’ve never seen that happen. Given enough usage, applications and requirements inevitably grow and evole over time as new problems and more efficient processes are discovered.
Mixins offer a more flexible approach.
“Favour object composition over class inheritance” the Gang of Four, “Deign Patterns: Elements of Reusable Object Oriented Software:
Mixins are a form of object compositions, where component features get mixed into a composite object so that properties of each mixin become properties of the composite object.
The term “mixin” in OOP comes from mixin ice-cream shops. Instead of having a whole lot of ice-cream flavours in different pre-mixed buckets, yo have vanilla ice-cream, and a bunch of separate ingredients that could be mixed in to create custom flavours for each customer.
Object mixins are similar: you start with an empty object and mix in features to extend it. Because javascript supports dynamic object extension and objects without classes, using object mixins is trivially easy in javascript - so much so that it is the most common form if inheritance in javascript by a huge margin. Let’s have a look at an example:
const chocolate = {
hasChocolate : () => true
};
const caramelSwirl = {
hasCaramelSwirl : () => true
};
const pecans = {
hasPecans : () => true
};
const iceCream = Object.assign({}, chocolate, caramelSwirl, pecans );
/* Or if your environment supports object spread
const iceCream = { ...chocolate, ...caramelSwirl, ..pecans };
*/
console.log( `
hasChocolate : ${ iceCream.hasChocolate() }
hasCaramelSwirl : ${ iceCream.hasCaramelSwirl() }
hasPecans : ${ iceCream.hasPecans() }
` );
/* Which logs:
hasChocolate : true
hasCaramelSwirl : true
hasPecans : true
*/Functional inheritance is the process of inheriting features by applying an augmenting function toan object instance. The function supplies a closure scope which you can use to keep some data private. The augmenting function uses dynamic object extension to extend the object instance with new properties and methods.
Take a ganders at an example from Douglas Crockford, who coined the term:
// Base object factory
function base( spec ){
var that = {}; // create an empty object
that.name = spec.name; // Add it a "name" property
return that; // Return object
}
// Construct a child object, inheriting from "base"
function child( spec ){
// Create the object through the "base" constructor
var that = base( spec );
that.sayHello = function(){ // Augment that object
return "Hello, I'm " + that.name;
};
}
// Usage
var result = child({ name : "a functional object" });
console.log( result.sayHello()); // "Hello, I'm a functional object"Because child() is tightly coupled to
base(), when you add grandchild(),
greatGrandchild() etc…, you’ll opt into most of the common
problems from class inheritance.
Functional mixins are composable functions which mix new properties or behaviours with properties from a given object. Functional mixins don’t depend on or require a base factory or constructor: simply pass any arbitrary object into a mixin and it will be extended.
An example:
const flying = o => {
let isFlying = false;
return Object.assign({}, o, {
fly(){
isFlying = true;
return this;
},
isFlying : () => isFlying,
land(){
isFlying : false;
return this;
}
});
};
const bird = flying({});
console.log( bird.isFlying()); // false
consoe.log( bird.fly().isFlying()); // trueNotice that when we call flying() we need to pass an
object in to be extended. Functional mixins are designed for functional
composition. Let’s create something to compose with:
const quacking = quack => o => Object.assign({}, o, {
quack : () => quack
});
const quacker = quacking( "Quack!" )({});
console.log( quacker.quack()); // "Quack!"Functional mixins can be composed with simple function composition:
const createDuck = quack => quacking( quack )( flying({}));
const duck = createDuck( "Quack!" );
console.log( duck.fly().quack());That looks a little awkward to read, though. It can also be a bit tricky to debug or re-arrange the order of composition.
Of course, this is standard function composition, and we already know
some better ways to do that using compose() or
pipe(). If we use pipe() to reverse the
function order, the composition will read like
Object.assign({}, … ) or
{ ...object, ...spread } – preserving the same order of
precedence. In case of property collisions, the last object in wins.
const pipe = ( ...fns ) => x => fns.reduce(( y, f ) => f( y ), x );
// OR… import pipe from "lodash/fp/flow";
const createDuck = quack => pipe(
flying,
quacking( quack )
)({});
const duck = createDuck( "Quack!" );
console.log( duck.fly().quack());You should always use the simplest possible abstraction to solve the problem you’re working on. Start with a pure function. If you’re in need of an object with a persistent state, try a factory function. If you need to build more complex objects, try functional mixins.
Here are some good use-cases for functional mixins: * Application
state management, e.g. a Redux store. * Certain cross-cutting concerns
and services, e.g. a centralized logger. * Composable functional data
types, e.g. the javascript Array type
implements Semigroup, Functor and
Foldable. Some algebraic structures can be derived in terms
of other algebraic structures, meaning that certain derivations can be
composed into a new data type without customisation.
React users: class is fine for
lifecycle hooks because callers aren’t expected to use new,
and documented best-practice is to avoid inheriting from any components
other than the React-provided base components. I use and recommend HOCs
(Higher Order Components) with function composition to compose UI
components.
Most problems can be elegantly solved using pure functions. The same is not true of functional mixins. Like class inheritance, functional mixins can cause problems of their own. In fact, it’s possible to faithfully reproduce all fo the features and problems of class inheritance using functional mixins.
You can avoid that, though, using the following advice: * Use the
simplest practical implementation. Start on the left and move to the
right only as needed: pure functions > factories > functional
mixins > classes. * Avoid the creation of is-a
relationships between objects, mixins or data types. * Avoid implicit
dependencies between mixins — wherever possible, functional mixins
should be self-contained, and have no knowledge of other mixins. *
“Functional mixins” doesn’t mean “functional programming”. * There may
be side-effects when you access a property using
Object.assign() or object spread syntax
({ ... }). You’ll also skip any non-enumerable properties.
ES2017 added Object.getOwnPropertyDescriptors() to get
around this problem.
If you’re tempted to use functional mixins in any scope larger than
your own small projects, you should probably look at
stamps, instead. The Stamp Specification is a standard for
sharing and reusing composable factory functions, with built-in
mechanisms to deal with property descriptors, prototype delegation and
so on.
I rely mostly on function composition to compose behaviour and
application structure and only rarely need functional mixins or stamps.
I never use class inheritance unless I’m descending directly from a
third-party base class such as React.class. I never build
my own inheritance hierarchies.
Class inheritance is very rarely (perhaps never) the best approach in
javascript but that choice is sometimes made by a
library or framework that you don’t control. In that case, using
class is sometimes practical, provided the library: 1. Does
not require you to extend your own classes (i.e. does not require you to
build multi-level class hierarchies). 2. Does not require you to
directly use the new keyword — in other words, the
framework handles instantiation for you
Both Angular 2+ and React meet those requirements so you can safely use classes with them as long as you don’t extend you own classes. React allows you to avoid using classes if you wish, but your components may fail to take advantage of optimisations built into React’s base classes and your components won’t look like the components in documentation examples. In any case, you should always prefer the function form for React components when it makes sense.
In some browsers, classes may provide javascript
engine optimisations that are not available otherwise. In almost all
cases, those optimisations will not have a significant impact on your
apps performance. In fact, it’s possible to go many years without ever
needing to worry about class performance differences.
Object creation and property access is always very fast (millions of
ops/sec) regardless of how you build your objects.
That said, authors of general purpose utility libraries similar to
RxJS, Lodash, etc… should investigate possible performance benefits of
using class to create object instances. Unless you have
measured a significant bottleneck that you can provably and
substantially reduce using class, you should optimise for
clean, flexible code instead of worrying about performance.
You may be tempted to create functional mixins designed to work together. Imagine you want to build a configuration manager for your app that logs warnings when you try to access configuration properties that don’t exist. It’s possible to build it like this:
// in it's own module…
const withLogging = logger => o => Object.assign({}, o, {
log( text ){
logger( text )
}
});
// in a different module with no explicit mention of
// withLogging — we just assume it's there…
const withConfig = config => ( o = {
log : ( text = "" ) => console.log( text )
}) => Object.assign({}, o, {
get( key ){
return config[ key ] == undefined ?
// vvv implicit dependency here… oops! vvv
this.log( `Missing config key: ${ key }` ) :
// ^^^ implicit dependency here… oops! ^^^
config[ key ];
}
});
// in yet another module that imports withLogging and imports withLogging and withConfig…
const createConfig = ({ initialConfig, logger }) =>
pipe(
withLogging( logger ),
withConfig( initialConfig )
)({})
;
// elsewhere…
const initialConfig = {
host : "localhost"
};
const logger = console.log.bind( console );
const config = createConfig({ initialConfig, logger });
console.log( config.get( "host" )); // "localhost"
config.get( "notThere" ); // "Missing config key: notThere"However, it’s also possible to build it like this:
// import withLogging() explicitly in withConfig module
import withLogging form "./with-logging";
const addConfig = config => o => Object.assign({}, o, {
get( key ){
return config[ key ] == undefined ?
this.log( `Missing config key: ${ key }` ) :
config[ key ];
}
});
const withConfig = ({ initialConfig, logger }) => o =>
pipe(
// vvv compose explicit dependency in here vvv
withLogging( logger ),
// ^^^ compose explicit dependency in here ^^^
addConfig( initialConfig )
)( o );
// The factory only needs to know about withConfig now…
const createConfig = ({ initialConfig, logger }) =>
withConfig({ initialConfig, logger )({});
// elsewhere, in a different module…
const initialConfig = {
host : "localhost"
};
const logger = console.log.bind( console );
const config = createConfig({ initialConfig, logger });
console.log( config.get( "host" )); // "localhost"
config.get( "notThere" ); // "Missing config key: notThere"The correct choice depends on a lot of factors. It is valid to require a lifted data type for a functional mixin to act on, but if that’s the case, the API contract should be made explicitly in the function signature an API documentation.
That’s the reason that the implicit version has a default value for
o in the signature. Since javascript lack
type annotation capabilities, we can fake it by providing default
values:
const withConfig = config => ( o = {
log : ( text = "" ) => console.log( text )
}) => Object.assign({}, o, {
// …
});If you’re using Typescript or Flow, it’s probably better to declare an explicit interface for your object requirements.
“Functional” in the context of functional mixins does not always have the same purity connotations as “functional programming”. Functional mixins are commonly used in OOP style, complete with side-effects. Many functional mixins will alter the object argument you pass to them. Caveat emptor.
By the same token, some developers prefer a functional programming
style, and will maintain an identity reference to the object you pass
in. You should code your mixins and the code that uses them assuming a
random mix of both styles. That means that if you need to return the
object instance, always return this instead of a reference
to the instance object in the closure — in functional code, chances are
those are not references to the same objects. Additionally, always
assume that the object instance will be copied by assignment using
Object.assign() or { ...object, ...spread }
syntax. That means that if you set non-enumerable properties they will
probably not work on the final object:
const a = Object.defineProperty({}, "a", {
enumerable : false,
value : "a"
});
const b = {
b : "b"
};
console.log({ ...a, ...b }); // { b : "b" }Should one use functional mixins that you didn’t create in your functional code, don’t assume the code is pure. Assume that the base object may be mutated and assume that there may be side-effects & no referential transparency guarantees, i.e. it is frequently unsafe to memoize factories composed of functional mixins.
Functional mixins are composable factory functions which add
properties and behaviours to objects like stations in an assembly line.
They are a great way to compose behaviours from multiple source features
(has-a, uses-a can-do ), as opposed to inheriting all the
features of a given class (is-a).
Be aware, “functional mixins” doesn’t imply “functional programming” — it simply means, “mixins using functions”. Functional mixins can be written using a functional programming style, avoiding side-effects and preserving referential transparency, but that is not guaranteed. There may be side-effects and nondeterminism in third-party mixins.
Start with the implementation and move to more complex implementations only as required:
Functions > objects > factory functions > functional mixins > classes
A factory function is any function which is not a class or
constructor that returns a (presumably new) object. In
javascript, any function can return an object. When it
does so without the new keyword, it’s a factory
function.
Factory functions have always been attractive in
javascript because they offer the ability to easily
produce object instances without diving into the complexities of classes
and the new keyword.
Javascript provides a very handy object literal syntax. It looks something like this:
const user = {
userName : "echo",
avatar : "echo.png"
};Like JSON (which is based on javascript’s object
literal notation), the left side of the : is the property
name and the right side is the value. You can access props with dot
notation: console.log( user.userNname ); // "echo".
You can access computed property names using square bracket notation:
const key = "avatar"; console.log( user[ key ]); // "echo.png".
If you have variables in-scope with the same name as your intended
property names, you can omit the colon and the value in the object
literal creation:
const userName = "echo";
const avatar = "echo.png";
const user = {
userName,
avatar
};
console.log( user );
// { avatar : "echo.png", userName : "echo" }Object literals support concise method syntax. We can add a
.setUserName() method:
const userName = "echo";
const avatar = "echo.png";
const user = {
userName,
avatar,
setUser( userName ){
this.userName = userName;
return this;
}
};
console.log( user.setUserName( "Foo" ).userName ); // "Foo"In concise methods, this refers to the object which the
method is called on. To call a method on an object, simply access the
method using object dot notation and invoke it by using parentheses,
e.g. game.play() would apply .play() to the
game object. In order to apply a method using dot notation,
that method must be a property of the object in question. You can also
apply a method to any other arbitrary methods, .call(),
.apply() or .bind().
In this case, user.setUserName( "Foo" ) applies
.setUserName() to user, so
this === user. In the .setUserName() method,
we change the .userName property on the user
object via its this binding and return the same object
instance for method chaining.
Should you need to create many objects, you’ll want to combine the power of object literals and factory functions. With a factory function, you can create as many user objects as you want. If you’re building a chat app, for instance, you can have a user object representing the current user, and a lot a lot of other user objects representing all the other users who are currently signed in and chatting, so you can display their names and avatars, too.
Let’s turn our user object into a
createUser() factory:
const createUser = ({ userName, avatar }) => ({
userName,
avatar,
setUserName( userName ){
this.userName = userName;
return this;
}
}):
console.log( createUser({ userName : "echo", avatar : "echo.png" }));
/*
{
"avatar" : "echo.png",
"userName" : "echo",
"setUserName" : [Function setUserName]
}
*/Arrow functions, =>, have an implicit return feature:
if the function body consists of a single expression, you can omit the
return keyword: () => "foo" is a function
that takes no parameters and returns the string "foo".
Be careful when you return object literals. By default,
javascript assumes you want to create a function body
when you use braces, e.g. { broken : true }. If you want to
use an implicit return for an object literal, you’ll need to
disambiguate by wrapping the object literal in parentheses:
const noop = () => { foo : "bar" };
console.log( noop()); // undefined
const createFoo = () => ({ foo : "bar" });
console.log( createFoo()); // { foo : "bar" }In the first example, foo: is interpreted as a label,
and bar is interpreted as an expression that doesn’t get
assigned or returned. The function returns undefined.
In the createFoo() example, the parentheses force the
braces to be interpreted as an expression to be evaluated rather than a
function body block.
Pay special attention to the function signature:
const createUser = ({ userName, avatar }) => ({.
In this line, the braces ({, }) represent object
destructuring. This function takes one argument (an object) but
destructures two formal parameters from that single argument,
userName and avatar. Those parameters can then
be used as variables in the function body scope. You can also
destructure arrays:
const swap = ([ first, second ]) => [ second, first ];
console.log( swap([ 1, 2 ])); // [ 2, 1 ]And you can use the rest and spread syntax (...varName)
to gather the rest of the values from the array (or a list
of arguments), and then spread those array elements back
into individual elements:
const rotate = ([ first, ...rest ]) => [ ...rest, first ];
console.log( rotate([ 1, 2, 3 ])); // [ 2, 3, 1 ]Earlier we used square bracket computed property access notation to dynamically determine which object property to access:
const key = "avatar";
console.log( user[ key ]); // "echo.png"We can also compute the value of keys to assign to:
const arrToObj = ([ key, value ]) => ({[ key ] : value });
console.log( arrToObj([ "foo", "bar" ])); // { foo : "bar" }In this example, arrToObj takes an array
consisting of a key/value pair (aka a tuple) and converts it into an
object. Since we don’t know the name of the key, we need to compute the
property name in order to set the key/value pair on the object. For
that, we borrow the idea of square bracket notation from computed
property accessors, and reuse it in the context of building an object
literal: {[ key ] : value }.
After the interpolation is done, we end up with the final object:
{ "foo" : "bar" }.
Functions in javascript support default parameter values, which have several benefits:
1 implies that the parameter can take a member of the
Number type.Using default parameters we can document the expected interface for
our createUser factory, and automatically fill in
Anonymous details if the user’s info is not supplied:
const createUser = ({
userName = "Anonymous",
avatar = "anon.png"
} = {}) => ({
userName,
avatar
});
console.log(
// { userName : "echo", avatar : "anon.png" }
createUser({ userName : "echo" }),
// { userName : "Anonymous", avatar : "anon.png" }
createUser()
);The last = {} bit just before the parameter signature
closes means that if nothing gets passed in for this parameter, we’re
going to use empty object as the default if no argument is passed in.
When you try to destructure values from the empty object, the default
values for properties will get used automatically, because that’s what
default values do: replace undefined with some predefined
value.
Without the = {} default value,
createUser() with no arguments would throw an error because
you can’t try to access properties from undefined.
Javascript does not have any native type annotations as of this writing, but several competing formats have spring up over the years to fill the gaps, including JSDoc, Facebook’s Flow and Microsoft’s TypeScript. I use rtype for documentation — a notation I find much more readable than TypeScript for functional programming.
At the time of this writing, there is no clear winner for type annotations. None of the alternatives have been blessed by the javascript specification and there seem to be clear shortcomings in all of them.
Type inference is the process of inferring types based on the context in which they are used. In javascript, it is a very good alternative to type annotations.
If you provide enough clues for inference in your standard javascript function signatures, you’ll get most of the benefits of type annotations with none of the costs or risks.
Even if you decide to use a tool like TypeScript or Flow, you should do as much as you can with type inference, and save the type annotations for situations where type inference falls short. For example, there’s no native way in javascript to specify a shared interface. That’s both easy ans useful with TypeScript or rtype.
Tern.js is a popular type inference tool for javascript that has plugins for many code editors and IDEs.
Microsoft’s Visual Studio Code doesn’t need Tern.js because it brings the type inference capabilities of TypeScript to regular javascript code.
When you specify default parameters for functions in javascript, tools capable of type inference such as Tern.js, TypeScript and Flow can provide IDE hints to help you use the API you’re working with correctly.
Without defaults, IDEs (and frequently, humans) don’t have enough
hints to figure out the expected parameter type. Without defaults, the
type is unknown for userName.
With defaults, IDEs (and frequently, humans) can infer the types from
the examples. With defaults, the IDE can suggest that
userName is expecting a string.
It doesn’t always make sense to restrict a parameter to a fixed type (that would make generic functions and higher order functions difficult), but when it does make sense, default parameters are often the best way to do it, even if you’re using TypeScript or Flow.
Factories are great at cranking out objects using a nice calling API. Usually, they’re all you need, but once in a while, you’ll find yourself building similar features into different types of objects, and you’ll want to abstract those features into functional mixins so you can reuse them more easily.
That’s where functional mixins shine. Let’s build a
withConstructor mixin to add the .constructor
property to all object instances. with-constructor.js:
const withConstructor = constructor => o => {
const proto = Object.assign({},
Object.getPrototypeOf( o ),
{ constructor }
);
return Object.assign( Object.create( proto ), o );
};Now you can import it and use it with other mixins:
import withConstrutor from "./with-constructor";
const pipe = ( ...fns ) => x => fns.reduce(( y, f ) => f( y ), x );
// or `import pipe from "lodash/fp/flow";`
// Set up some functional mixins
const withFlying = o => {
let isFlying = false;
return {
...o,
fly(){
isFlying = true;
return this;
},
land(){
isFlying = false;
return this;
},
isFlying : () => isFlying
}
};
const withBattery = ({ capacity }) => o => {
let percentCharged = 100;
return {
...o,
draw( percent ){
const remaining = percentCharged - percent;
percentCharged = remaining > 0 ? remaining : 0;
return this;
},
getCharge : () => percentCharged,
get capacity(){
return capacity;
}
};
};
const createDrone = ({ capacity : "3000mAh" }) => pipe(
withFlying,
withBattery({ capacity }),
withConstructor( createDrone )
)({});
const myDrone = createDrone({ capacity : "5000mAh" });
console.log( `
can fly : ${ myDrone.fly().isFlying() === true }
can land : ${ myDrone.land().isFlying() === false }
battery capacity : ${ myDrone.capacity }
battery status : ${ myDrone.draw( 50 ).getCharge() }%
battery drained : ${ myDrone.draw( 75 ).getCharge() }%
` );
console.log( `
constructor linked : ${ myDrone.constructor === createDrone }
` );As you can see, the reusable withConstructor() mixin is
simply dropped into the pipeline with other mixins.
withBattery() could be used with other kinds of objects,
like robots, electric skateboards or portable device chargers.
withFlying() could be used to model flying cars, rockets or
air balloons.
Composition is more of a way of thinking than a particular technique in code. You can accomplish it in many ways. Function composition is just the easiest way to build it up from scratch and factory functions are a simple way to wrap a friendly API around the implementation details.
ES6 provides a convenient syntax for dealing with object creation and
factory functions. Most of the time, that’s all you’ll need but because
this is javascript, there’s another approach that makes
it feel more like Java: the class
keyword.
In javascript, classes are more verbose & restrictive than factories, and a bit of a minefield when it comes to refactoring, but they’ve also been embraced by major front-end frameworks like React and Angular. There are a couple of rare use-cases that make the complexity worthwhile.
“Sometimes, the elegant implementation is just a function. Not a method. Not a class. Not a framework. Just a function.” ~ John Carmack
Start with the simplest implementation and move to more complex implementations only as required. When it comes to objects, that progression looks a bit like this:
Pure function -> factory -> functional mixin -> class
Previously, we examined factory functions and looked at how easy it
is to use them for composition using functional mixins. Now we’re going
to look at classes in more detail, and examine how the mechanics of
class get in the way of composition.
We’ll also take a look at the good use-cases for classes and how to use them safely.
ES6 includes a convenient class syntax, so you may be
wondering why we should care about factories at all. The most obvious
difference is that constructors and class require the
new keyword. But what does new actually
do?
this to it in the
constructor function.this, unless you explicitly return
another object.[[Prototype]] (an internal reference)
to Constructor.prototype, so that
Object.getPrototypeOf( instance ) === Constructor.prototype.instance.constructor === Constructor.All of that implies that, unlike factory functions, classes are not a
good solution for composing functional mixins. You can still achieve
composition using class, but it’s a much more complex
process, and as you’ll see, the additional costs are usually not worth
the extra effort.
You may eventually need to refactor from a class to a factory
function, and if you require callers to use the new
keyword, that refactor could break client code you’re not even aware of
in a couple of ways. First, unlike classes and constructors, factory
functions don’t automatically wire up a delegate prototype link.
The [[Prototype]] link is used for prototype delegation,
which is a convenient way to conserve memory if you have millions of
objects, or to squeeze a micro-performance boost out of your program if
you need to access tens of thousands of properties on an object within a
16ms render loop cycle.
If you don’t need to micro-optimise memory or performance, the
[[Prototype]] link can do more harm than good. The
prototype chain powers the instanceof operator in
javascript, and unfortunately instanceof
lies for two reasons:
In ES5, the Constructor.prototype link was dynamic and
reconfigurable, which could be a handy feature if you need to create an
abstract factory — but if you use that feature, instanceof
will give you false negatives if the Constructor.prototype
does not currently reference the same object in memory that the instance
[[Prototype]] references:
class User{
constructor({ userName, avatar }){
this.userName = userName;
this.avatar = avatar;
}
}
const currentUser = new User({
userName : "Foo",
avatar : "foo.png"
});
User.prototype = {};
console.log(
currentUser instanceof User, // <- false
currentUser // { avatar : "foo.png", userName : "Foo" }
);Chrome solves the problem by making the
Constructor.prototype property
configurable: false in the property descriptor. However,
Babel does not currently mirror that behaviour, so
Babel compiled code will behave like ES5 constructors.
V8 silently fails if you attempt to reconfigure the
Constructor.prototype property. Either way, you won’t get
the results you expected. Worse: the behaviour is inconsistent. I don’t
recommend reassigning Constructor.prototype.
A more common problem is that javascript has
multiple execution contexts — memory sandboxes where the same code will
access different physical memory locations. If you have a constructor in
a parent frame, for example, and the same constructor in an
iframe, the parent frame’s
Constructor.prototype will not reference the same memory
location as the Constructor.prototype in the
iframe. Object values in javascript are
memory references under the hood, and different frames point to
different locations in memory, so === checks will fail.
Another problem with instanceof is that it is a nominal
type check rather than a structural type check, which means that if you
start with a class and later switch to an abstract factory,
all the calling code using instanceof won’t understand new
implementations even if they satisfy the same interface contract. For
example, say you’re tasked with building a music player interface. Later
on the product team tells you to add support for 360 videos. They all
supply the same controls: play, stop, rewind, fast forward.
But if you’re using instanceof checks, members of your
video interface class won’t satisfy the
foo instanceof AudioInterface checks already in the
codebase.
They’ll fail when they should succeed. Sharable interfaces in other languages solve this problem by allowing a class to declare that it implements a specific interface. That’s not currently possible in javascript.
The best way to deal with instanceof in
javascript is to break the delegate prototype link if
it’s not required, and let instanceof fail hard for every
call. That way you won’t get a false sense of reliability. Don’t listen
to instanceof and it will never lie to you.
The .constructor property is a rarely used feature in
javascript, but it could be very useful, and it’s a
good idea to include it on your object instances. It’s mostly harmless
if you don’t try to use it for type checking (which is unsafe for the
same reasons instanceof is unsafe).
In theory, .constructor could be useful to make genetic
functions which are capable of returning a new instance of whatever
object you pass in.
In practice, there are many different ways to create new instances of things in javascript — having a reference to the constructor is not the same thing as knowing how to instantiate a new object with it — even for seemingly trivial purposes, such as creating an empty instance of a given object:
// Return an empty instance of any object type?
const empty = ({ constructor } = {}) => constructor ?
new constructor() :
undefined;
const foo = [ 10 ];
console.log(
empty( foo ) // []
);It seems to work with Arrays. Let’s try it with
Promises:
const empty = ({ constructor } = {}) => constructor ?
new constructor() :
undefined;
const foo = Promise.resolve( 10 );
console.log(
empty( foo ) // [TypeError: Promise resolver undefined is
// not a function]
);Note the new keyword in the code. That’s most of the
problem. It’s not safe to assume that you can use the new
keyword with any factory function. Sometimes, that will cause
errors.
What we would need to make this work is to have a standard way to
pass a value into a new instance using a standard factory function that
doesn’t require new. There is a specification for that : a
static method on any factory or constructor called .of().
The .of() method is a factory that returns a new instance
of the data type containing whatever you pass into
.of().
We could use .of() to create a better version of the
generic empty() function:
// Return an empty instance of any type?
const empty = ({ constructor } = {}) => constructor.of ?
constructor.of() :
undefined;
const foo = [ 23 ];
console.log(
empty( foo ) // []
);Unfortunately, the static .of() method is just beginning
to gain support in javascript. The Promise
object does have a static method that acts like .of(), but
it’s called .resolve() instead so our generic
empty() won’t work with promises. Likewise, there’s no
.of() for strings, numbers, objects, maps, weak maps or
sets in javascript as of this writing.
If support for the .of() method catches on in other
standard javascript data types, the
.constructor property could eventually become a much more
useful feature of the language. We could use it to build a rich library
of utility functions capable of acting on a variety of functors, monads,
and other algebraic datatypes.
It’s easy to add support for .constructor and
.of() to a factory:
const createUser = ({
userName = "Anonymous",
avatar = "anon.png",
} = {}) => ({
userName,
avatar,
constructor : createUser
});
createUser.of = createUser;
// testing .of an .constructor
const empty = ({ constructor } = {}) => constructor.of ?
constructor.of() :
undefined;
const foo = createUser({ userName : "Empty", avatar : "me.png" });
console.log(
empty( foo ), // { avatar : "anon.png", userName : "Anonymous" }
foo.constructor === createUser.of, // true
createUser.of === creatUser // true
);You can even make .constructor non-enumerable by adding
to the delegate prototype with Object.create():
const createUser = ({
userName = "Anonymous",
avatar = "anon.png"
} = {}) => Object.assign(
Object.create({
constructor : createUser
}), {
userName,
avatar
}
);Factories allow increased flexibility in the following ways: *
Decouple instantiation details from calling code. * Allow you to return
arbitrary objects — for instance, to use an object pool to tame the
garbage collector. * Don’t pretend to provide any type guarantees so
callers are less tempted to use instanceof and other
unreliable type checking measures which might break code across
execution contexts or if you switch to an abstract factory. * Because
they don’t pretend to provide type guarantees, factories can dynamically
swap implementations for abstract factories, e.g. a media player that
swaps out the .play() method for different media types. *
Adding capability with composition is easier with factories.
While it’s possible to accomplish most of these goals using classes, it’s easier to do so with factories. There are fewer potential bug pitfalls, less complexity to juggle and a lot less code.
For these reasons, it’s often desirable to refactor from a
class to a factory but it can be a complex, error-prone
process. Refactoring from classes to factories is a common need in every
OO language. You can read more about it in “Refactoring: Improving the
Design of Existing Code” by Martin Fowler, Kent Beck, John Brant,
William Opdyke and Don Roberts.
Due to the fact that new changes the behaviour of a
function being called, changing from a class or constructor to a factory
function is a potentially breaking change. In other words, forcing
callers to use new could unwittingly lock callers into the
constructor implementation so new leaks potentially
breaking implementation details into the calling API.
As we have already seen, the following implicit behaviours can make
the switch a breaking change: * Absence of the
[[Prototype]] link from factory instances will break caller
instanceof checks. * Absence of the
.constructor property from factory instances could break
code that relies on it.
Both problems can be remedied by manually hooking those properties up
in your factories. Internally, you’ll also need to be mindful that
this may be dynamically bound from factory call sites,
which is not the case when callers use new. That can
complicate matters if you want to store alternate abstract factory
prototypes as static properties on the factory.
There is another problem too. All class callers must use
new. Leaving it off in ES6 will always throw:
class Foo{};
// TypeError: Class constructor Foo cannot be invoked without 'new'
const Bar = Foo();In ES6+, arrow functions are commonly used to create factories but
because arrow functions don’t have their own this binding
in javascript invoking an arrow function with
new throws an error:
const foo = () => ({});
// TypeError: foo is not a constructor
const bar = new foo();So if you try to refactor from a class to an arrow function factory, it will fail in native ES6 environments which is OK. Failing hard is a good thing.
But if you compile arrow functions to standard functions it will fail to fail. That’s bad because it should be an error. It will “work” while you’re building the app but potentially fail in production where it could impact the user experience or even prevent the app form working at all.
A change in the compiler default settings could break your app even if you didn’t change any of your own code. That gotcha bears repeating:
Warning: Refactoring from a class to an arrow function factory might seem to work with a compiler but if the code compiles the factory to a native arrow function your app will break because you can’t use
newwith arrow functions.
new Violates the Open/Closed PrincipleOur APIs should be open to extension but closed to breaking changes.
Since a common extension to a class is to turn it into a more flexible
factory, but that refactor is a breaking change, code that requires the
new keyword is closed for extension and open to breaking
changes. That’s the opposite of what we want.
The impact of this is larger than it seems at first. If your
class API is public, or if you work on a very large app
with a very large team, the refactor is likely to break code you’re not
even aware of. It’s a better idea to deprecate the class
entirely and replace it with a factory function to move forward.
That process changes a small technical problem that can be solved silently by code into an unbounded people problem that requires awareness, education and buy-in — a much more expensive refactor!
I’ve seen the new issue cause very expensive headaches
many times and it’s trivially easy to avoid.
Export a factory instead of a class.
class Keyword
and ExtendsThe class keyword is supposed to be a nicer syntax for
object creation patterns in javascript but it falls
short in several ways:
The primary purpose of class was to provide a friendly
syntax to mimic class from other languages in
javascript. The question we should ask ourselves though
is, does javascript really need to mimic
class from other languages?
Javascript’s factory functions provide a friendlier syntax out of the box with less complexity. Often, an object literal is good enough. If you need to create many instances, factories are a good next step.
In Java and C++, factories are more complicated than classes but they’re often worth building because they provide enhanced flexibility. In javascript, factories are less complicated and more flexible than classes.
Compare the class:
class User{
constructor({ userName, avatar }){
this.userName = userName;
this.avatar = avatar;
}
}
const currentUser = new User({
userName : "Foo",
avatar : "foo.png"
});Versus the equivalent factory:
const createUser = ({ userName, avatar }) => ({
userName,
avatar
});
const currentUser = createUser({
userName : "Foo",
avatar : "foo.png"
});With javascript and arrow function familiarity,
factories are clearly less syntax and easier to read. Maybe you prefer
to see the new keyword but there are good reasons to avoid
new. Familiarity bias may be holding you back.
What other arguments are there?
Good use-cases for delegate prototypes are rare.
class syntax is a little nicer than the equivalent
syntax for ES5 constructor functions but the primary purpose is to hook
up the delegate prototype chain. Good use-cases for delegate prototypes
are rare. It really boils down to performance.
class offers two kinds of performance optimisations:
property lookup optimisations and shared memory for properties stored on
the delegate prototype.
Most modern device shave RAM measured in gigabytes and any type of closure scope or property lookup is measured in hundreds of thousands or millions of operations per second. Performance differences are rarely measurable in the context of an application let alone impactful.
There are exceptions of course. RxJS used
class instances because they’re faster than closure scopes
but RxJS is a general purpose utility library that
might be used in the context of hundred of thousands of operations that
need to be squeezed into a 16ms render loop.
ThreeJS uses classes but ThreeJS is a 3d rendering library which might be used for game engines manipulating thousands of objects every 16ms.
It makes sense for libraries like ThreeJS & RxJS to go to extremes optimising wherever they can.
In the context of applications we should avoid premature optimisation and focus our efforts only where they’ll make a large impact. For most applications that means our network calls & payloads, animations, asset caching strategies, etc…
Don’t micro-optimise for performance unless you’ve noticed a performance problem, profiled your application code and pinpointed a real bottleneck. Instead you should optimise code for maintenance and flexibility.
Classes in javascript are dynamic and
instanceof checks don’t work across execution contexts so
type checking based on class is a non-starter. It’s
unreliable. It’s likely to cause bugs and make your application
unnecessarily rigid.
extendsClass inheritance causes several well-known problems that bear repeating: * Tight coupling: Class inheritance is the tightest form of coupling available in object-oriented design. * Inflexible hierarchies: Given enough time and users, all class hierarchies are eventually wrong for new use-cases but tight coupling makes refactoring difficult. * Gorilla/Banana problem: No selective inheritance. * Duplication by necessity: Due to inflexible hierarchies and the gorilla/banana problem, code reuse is often accomplished by copy/paste, violating DRY and defeating the entire purpose of inheritance in the first place.
The only purpose of extends is to create single-ancestor
class taxonomies. Some clever hacker will read this and say, “Ah ha! Not
so! You can do class composition!” To which I would answer, “ah, but now
you’re using object composition instead of class inheritance and there
are easier, safer ways to do that in javascript without
extends”.
With all the warnings out of the way, some clear guidelines emerge that can help you use classes safely:
instanceof — it lies because
javaScript is dynamic and has multiple execution
contexts, and instanceof fails in both situations. It can
also cause problems if you switch to an abstract factory down the
road.It’s OK to use class if:
new and don’t get lured into
the extends trap.In most situations factories will serve you better. Factories are simpler than classes or constructors in javascript. Always start with the simplest solution and progress to more complex solutions only as needed.
In javascript, the easiest way to compose is function composition and a function is just an object with methods attached. In other words, you can do this:
const t = value => {
const fn = () => value;
fn.toString = () => `t( ${ value })`;
return fn;
};
const someValue = t( 2 );
console.log(
someValue.toString() // "t( 2 )"
);This is a factory that returns instances of a numerical data type,
t. But notice that those instances aren’t simple objects.
Instead they’re functions and like any other function you can compose
them. Let’s assume the primary use case for it is to sum its members.
Maybe it would make sense to sum when they compose.
First, let’s establish some rules (four “=” means “equivalent to”): *
t( x )( t( 0 )) ==== t( x ) *
t( x )( t( 1 )) ==== t( x + 1 )
You can express this in javascript using the
convenient .toString() method we already created: *
t( x )( t( 0 )).toString() ==== t( x ).toString() *
t( x )( t( 1 )).toString() ==== t( x + 1 ).toString()
And we can translate those into a simple kind of unit test:
const assert = {
same : ( actual, expected, msg ) => {
if( actual.toString() !== expected.toString()){
throw new Error( `NOT OK: ${ msg }
Expected : ${ expected }
Actual : ${ actual }
`);
}
console.log( `OK: ${ msg }` );
}
};
{
const msg = "a value t( x ) composed with t( 0 ) === t( x )";
const x = 20;
const a = t( x )( t( 0 ));
const b = t( x );
assert.same( a, b, msg );
}
{
const msg = "a value t( x ) composed with t( 1 ) ==== t( x + 1 )";
const x = 20;
const a = t( x )( t( 1 ));
const b = t( x + 1 );
assert.same( a, b, msg );
}These tests will fail at first:
NOT OK: a value t( x ) composed with t( 0 ) ==== t( x )
Expected : t( 20 )
Actual : 20
But we can make them pass with 3 simple steps: 1. Change the
fn function into an add function that returns
t( value + n ) where n is the passed argument.
2. Add a .valueOf() method to the t type so
that the new add() function can take instances of
t() as arguments. 3. Assign the methods to the
add() function with Object.assign().
When you put it all together it looks like this:
const t = value => {
const add = n => t( value + n );
return Object.assign( add, {
toString : () => `t( ${ value } )`,
valueOf : () => value
});
};And then the tests pass: > OK: a value t( x ) composed with t( 0 )
==== t( x )
> OK: a value t( x ) composed with t( 1 ) ==== t( x + 1 )
Now you can composed values of t() with function
composition:
// Compose functions from top to bottom:
const pipe = ( ...fns ) => x => fns.reduce(( y, f ) => f( y ), x );
// Sugar to kick off the pipeline with an initial value:
const sumT = ( ...fns ) => pipe( ...fns )( t( 0 ));
sumT(
t( 2 ),
t( 4 ),
t( -1 ),
).valueOf(); // 5It doesn’t matter what shape your data takes as long as there is some composition operation that makes sense. For lists or strings, it could be concatenation. For DSP, it could be signal summing. Of course lots of different operations might make sense for the same data. The question is, which operation best represents the concept of composition? In other words, which operation would benefit most expressed like this?
const result = compose(
value1,
value2,
value3
);Moneysafe is an open source library that implements
this style of composable function datatypes.
Javascript’s Number type can’t accurately
represent certain fractions of dollars:
.1 + .2 === .3 //false.
Moneysafe solves the problem by lifting dollar
amounts to cents: yarn add moneysafe, then:
import { $ } form "moneysafe";
$( .1 ) + $( .2 ) === $( .3 ).cents; // trueThe ledger syntax takes advantage of the fact that Moneysafe lifts values into composable functions. It exposes a simple function utility called the ledger:
import { $ } from "moneysafe";
import { $$, subtractPercent, addPercent } from "moneysafe/ledger";
$$(
$( 40 ),
$( 60 ),
// subtract discount
subtractPercent( 20 ),
// add tax
addPercent( 10 )
).$; // 88The returned value is a value of the lifted money type. It exposes
the convenient .$ getter which converts the internal
floating-point cents value into dollars, rounded to the nearest cent.
The result is an intuitive interface for performing ledger-style money
calculations.
git clone https://github.com/ericelliott/moneysafe.gityarn install.yarn run watch.rm source/moneysafe.js && touch source/moneysafe.js.Take a look at the watch console tests again. You should see an
error. Your mission is to reimplement moneysafe.js from
scratch using the unit tests and documentation as your guide.
Once you have written your solution run the command
node moneysafe.test.js from the sources folder
to run the tests.
const m$ = ({
symbol = "$",
subUnitInBase = 100,
round = Math.round,
precision = 2
} = {}) => {
const subToBase = c => c / subUnitInBase;
const baseToSub = d => d * subUnitInBase;
const $ = d => {
const cents = baseToSub( d );
const sum = v => $( subToBase( cents + v ));
return Object.assign( sum, {
toString : () => `${ symbol }${ d.toFixed( precision )}`,
valueOf : () => round( cents ),
get $(){ return subToBase( round( cents )); },
get cents(){ return round( cents ); },
round : () => $.cents( cents ),
add : c => $.cents( c + cents ),
subtract : c => $.cents( cents - c ),
constructor : $
});
};
$.cents = c => $( subToBase( round( c )));
$.of = c => $( subToBase( c ));
return $;
};
const $ = m$();
const in$ = c => $.cents( c ).$;
module.exports = {
m$,
$,
in$
};const m$ = ({
centsPerDollar = 100,
decimals = 2,
symbol = '$',
round = Math.round
} = {}) => {
function $ (dollars, {
cents = round(dollars * centsPerDollar),
in$ = round(cents) / centsPerDollar
} = {}) {
const add = a$ => $.of(cents + a$);
const subtract = a$ => $.of(cents - a$);
return Object.assign(add, {
valueOf () {
return cents;
},
get cents () {
return round(cents);
},
get $ () {
return in$;
},
round () {
return $.of(round(cents));
},
add,
subtract,
constructor: $,
toString () {
//return `${ symbol }${ this.$.toFixed(decimals) }`;
}
});
}
$.of = cents => $(undefined, { cents });
$.cents = cents => $.of(round(cents));
return $;
};
const $ = m$();
const in$ = n => $.cents(n).$;
module.exports = {
m$,
$,
in$
};How did you do?
“Once you understand monads, you immediately become incapable of explaining them to anyone else” Lady Monadgreen’s curse ~ Gilad Bracha (used famously by Douglas Crockford)
“Dr. Hoenikker used to say that any scientist who couldn’t explain to an eight-year-old what he was doing was a charlatan.” ~ Kurt Vonnegut’s novel Cat’s Cradle
If you go searching the internet for “monad” you’re going to get bombarded by impenetrable category theory math and a bunch of people “helpfully” explaining monads in terms of burritos and space suits.
Monads are simple. The lingo is hard. Let’s cut to the essence.
A monad is a way of composing functions that require
context in addition to the return value, such as computation, branching,
or I/O. Monads type lift, flatten and map so that the types line up for
lifting functions a => M(b), making them composable.
It’s a mapping from some type a to some type b
along with some computational context, hidden in the implementation
details of lift, flatten, and map:
a => bFunctor(a) => Functor(b)Monad(Monad(a)) => Monad(b)But what do “flatten” and “map” and “context” mean?
a
and return a b”. Given some input, return some output.a => b to the value inside the
context, and return a new value b wrapped inside the same
kind of context. Observables on the left? Observables on the right:
Observable(a) => Observable(b). Arrays on the left side?
Arrays on the right side: Array(a) => Array(b).a => F(a)
(Monads are a kind of functor).F(a) => a.Example:
const x = 20; // Some data of type `a`
const f = n => n * 2; // A function from `a` to `b`
const arr = Array.of(x); // The type lift.
// JS has type lift sugar for arrays: [x]// .map() applies the function f to the value x
// in the context of the array.
const result = arr.map(f); // [40]In this case, Array is the context, and x
is the value we’re mapping over.
This example did not include arrays of arrays, but you can flatten
arrays in JS with .concat():
[].concat.apply([], [[1], [2, 3], [4]]); // [1, 2, 3, 4]Regardless of your skill level or understanding of category theory, using monads makes your code easier to work with. Failing to take advantage of monads may make your code harder to work with (e.g., callback hell, nested conditional branches, more verbosity).
Remember, the essence of software development is composition, and monads make composition easier. Take another look at the essence of what monads are:
a => b which lets you compose
functions of type a => bFunctor(a) => Functor(b),
which lets you compose functions F(a) => F(b)Monad(Monad(a)) => Monad(b), which lets you compose
lifting functions a => F(b)These are all just different ways of expressing function composition. The whole reason functions exist is so you can compose them. Functions help you break down complex problems into simple problems that are easier to solve in isolation, so that you can compose them in various ways to form your application.
The key to understanding functions and their proper use is a deeper understanding of function composition.
Function composition creates function pipelines that your data flows through. You put some input in the first stage of the pipeline, and some data pops out of the last stage of the pipeline, transformed. But for that to work, each stage of the pipeline must be expecting the data type that the previous stage returns.
Composing simple functions is easy, because the types all line up
easily. Just match output type b to input type
b and you’re in business:
g: a => b
f: b => c
h = f(g(a)): a => cComposing with functors is also easy if you’re mapping
F(a) => F(b) because the types line up:
g: F(a) => F(b)
f: F(b) => F(c)
h = f(g(Fa)): F(a) => F(c)But if you want to compose functions from a => F(b),
b => F(c), and so on, you need monads. Let’s swap the
F() for M() to make that clear:
g: a => M(b)
f: b => M(c)
h = composeM(f, g): a => M(c)Oops. In this example, the component function types don’t line
up! For f’s input, we wanted type b, but
what we got was type M(b) (a monad of b).
Because of that misalignment, composeM() needs to unwrap
the M(b) that g returns so we can pass it to
f, because f is expecting type b,
not type M(b). That process (often
called .bind() or .chain()) is where
flatten and map happen.
It unwraps the b from M(b) before passing
it to the next function, which leads to this:
g: a => M(b) // flattens to => b
f: b // maps to => M(c)
h composeM(f, g): a // flatten(M(b)) => b => map(b => M(c)) => M(c)Monads make the types line up for lifting functions
a => M(b), so that you can compose them.
In the above diagram, the flatten from
M(b) => b and the map from b => M(c)
happens inside the chain from a => M(c).
The chain invocation is handled inside
composeM(). At a high level, you don’t have to worry about
it. You can just compose monad-returning functions using the same kind
of API you’d use to compose normal functions.
Monads are needed because lots of functions aren’t simple mappings
from a => b. Some functions need to deal with side
effects (promises, streams), handle branching (Maybe), deal with
exceptions (Either), etc…
Here’s a more concrete example. What if you need to fetch a user from an asynchronous API, and then pass that user data to another asynchronous API to perform some calculation?:
getUserById(id: String) => Promise(User)
hasPermision(User) => Promise(Boolean)Let’s write some functions to demonstrate the problem. First, the
utilities, compose() and trace():
const compose = (...fns) => x => fns.reduceRight((y, f) => f(y), x);const trace = label => value => {
console.log(`${ label }: ${ value }`);
return value;
};Then some functions to compose:
{
const label = 'API call composition'; // a => Promise(b)
const getUserById = id => id === 3 ?
Promise.resolve({ name: 'Kurt', role: 'Author' }) :
undefined
; // b => Promise(c)
const hasPermission = ({ role }) => (
Promise.resolve(role === 'Author')
); // Try to compose them. Warning: this will fail.
const authUser = compose(hasPermission, getUserById); // Oops! Always false!
authUser(3).then(trace(label));
}When we try to compose hasPermission() with
getUserById() to form authUser() we run into a
big problem because hasPermission() is expecting a
User object and getting a Promise(User)
instead. To fix this, we need to swap out compose() for
composePromises() — a special version of compose that knows
it needs to use .then() to accomplish the function
composition:
{
const composeM = chainMethod => (...ms) => (
ms.reduce((f, g) => x => g(x)[chainMethod](f))
); const composePromises = composeM('then'); const label = 'API call composition'; // a => Promise(b)
const getUserById = id => id === 3 ?
Promise.resolve({ name: 'Kurt', role: 'Author' }) :
undefined
; // b => Promise(c)
const hasPermission = ({ role }) => (
Promise.resolve(role === 'Author')
); // Compose the functions (this works!)
const authUser = composePromises(hasPermission, getUserById); authUser(3).then(trace(label)); // true
}We’ll get into what composeM() is doing, later.
Remember the essence of monads:
a => bFunctor(a) => Functor(b)Monad(Monad(a)) => Monad(b)In this case, our monads are really promises, so when we compose
these promise-returning functions, we have a Promise(User)
instead of the User that hasPermission() is
expecting. Notice that if you took the outer Monad()
wrapper off of Monad(Monad(a)), you’d be left with
Monad(a) => Monad(b), which is just the regular
functor .map(). If we had something that could flatten
Monad(x) => x, we’d be in business.
A monad is based on a simple symmetry — A way to wrap a value into a context, and a way to unwrap the value from the context:
a => M(a)M(a) => aAnd since monads are also functors, they can also map:
M(a) -> M(b)Combine flatten with map, and you get chain — function composition for monad-lifting functions, aka Kleisli composition, named after Heinrich Kleisli:
M(M(a)) => M(b)For monads, .map() methods are often omitted from the
public API. Lift + flatten don’t explicitly spell
out .map(), but you have all the ingredients you need to
make it. If you can lift (aka of/unit) and chain (aka bind/flatMap), you
can make .map():
const MyMonad = value => ({
// <... insert arbitrary chain and of here ...>
map (f) {
return this.chain(a => this.constructor.of(f(a)));
}
});So, if you define .of()
and .chain()/.join() for your monad, you can
infer the definition of .map().
The lift is the factory/constructor and/or
constructor.of() method. In category theory, it’s called
“unit”. All it does is lift the type into the context of the monad. It
turns an a into a Monad of a.
In Haskell, it’s (very confusingly) called return, which
gets extremely confusing when you try to talk about it out-loud because
nearly everyone confuses it with function returns. I almost always call
it “lift” or “type lift” in prose, and .of() in code.
That flattening process (without the map in .chain()) is
usually called flatten() or join(). Frequently
(but not always), flatten()/join() is omitted
completely because it’s built into .chain()/.flatMap().
Flattening is often associated with composition, so it’s frequently
combined with mapping. Remember, unwrapping + map are both needed to
compose a => M(a) functions.
Depending on what kind of monad you’re dealing with, the unwrapping
process could be extremely simple. In the case of the identity monad,
it’s just like .map(), except that you don’t lift the
resulting value back into the monad context. That has the effect of
discarding one layer of wrapping:
{ // Identity monad
const Id = value => ({
// Functor mapping
// Preserve the wrapping for .map() by
// passing the mapped value into the type
// lift:
map: f => Id.of(f(value)), // Monad chaining
// Discard one level of wrapping
// by omitting the .of() type lift:
chain: f => f(value), // Just a convenient way to inspect
// the values:
toString: () => `Id(${ value })`
});// The type lift for this monad is just
// a reference to the factory.
Id.of = Id;But the unwrapping part is also where the weird stuff like side effects, error branching, or waiting for async I/O typically hides. In all software development, composition is where all the real interesting stuff happens.
For example, with promises, .chain()
called .then(). Calling promise.then(f) won’t
invoke f() right away. Instead, it will wait for the
promise to resolve, and then call f() (hence the
name).
Example:
{
const x = 20; // The value
const p = Promise.resolve(x); // The context
const f = n =>
Promise.resolve(n * 2); // The function const result = p.then(f); // The application result.then(
r => console.log(r) // 40
);
}With promises, .then() is used instead
of .chain(), but it’s almost the same thing.
You may have heard that a promise is not strictly a monad. That’s
because it will only unwrap the outer promise if the value is a promise
to begin with. Otherwise, .then() behaves
like .map().
But because it behaves differently for promise values and other
values, .then() does not strictly obey all the mathematical
laws that all functors and/or monads must satisfy for all given values.
In practice, as long as you’re aware of that behavior branching, you can
usually treat them as either. Just be aware that some generic
composition tools may not work as expected with promises.
Let’s take a deeper look at the composeM function we
used to compose promise-lifting functions:
const composeM = method => (...ms) => (
ms.reduce((f, g) => x => g(x)[method](f))
);Hidden in that weird reducer is the algebraic definition of function
composition: f(g(x)). Let’s make it easier to spot:
{
// The algebraic definition of function composition:
// (f ∘ g)(x) = f(g(x))
const compose = (f, g) => x => f(g(x)); const x = 20; // The value
const arr = [x]; // The container // Some functions to compose
const g = n => n + 1;
const f = n => n * 2; // Proof that .map() accomplishes function composition.
// Chaining calls to map is function composition.
trace('map composes')([
arr.map(g).map(f),
arr.map(compose(f, g))
]);
// => [42], [42]
}What this means is that we could write a generalized compose utility
that should work for all functors which supply
a .map()method (e.g., arrays):
const composeMap = (...ms) => (
ms.reduce((f, g) => x => g(x).map(f))
);This is just a slight reformulation of the standard
f(g(x)). Given any number of functions of type
a -> Functor(b), iterate through each function and apply
each one to its input value, x. The .reduce()
method takes a function with two input values: An accumulator
(f in this case), and the current item in the array
(g).
We return a new function x => g(x).map(f) which
becomes f in the next application. We’ve already proved
above that x => g(x).map(f) is equivalent to lifting
compose(f, g)(x) into the context of the functor. In other
words, it’s equivalent to applying f(g(x)) to the values in
the container: In this case, that would apply the composition to the
values inside the array.
Performance Warning: I’m not recommending this for arrays. Composing functions in this way would require multiple iterations over the entire array (which could contain hundreds of thousands of items). For maps over an array, compose simple
a -> bfunctions first, then map over the array once, or optimize iterations with.reduce()or a transducer.
For synchronous, eager function applications over array data, this is overkill. However, lots of things are asynchronous or lazy, and lots of functions need to handle messy things like branching for exceptions or empty values.
That’s where monads come in. Monads can rely on values that depend on
previous asynchronous or branching actions in the composition chain. In
those cases, you can’t get a simple value out for simple function
compositions. Your monad-returning actions take the form
a => Monad(b) instead of a => b.
Whenever you have a function that takes some data, hits an API, and
returns a corresponding value, and another function that takes that
data, hits another API, and returns the result of a computation on that
data, you’ll want to compose functions of type
a => Monad(b). Because the API calls are asynchronous,
you’ll need to wrap the return values in something like a promise or
observable. In other words, the signatures for those functions are
a -> Monad(b), and b -> Monad(c),
respectively.
Composing functions of type g: a -> b,
f: b -> c is easy because the types line up:
h: a -> c is just a => f(g(a)).
Composing functions of type g: a -> Monad(b),
f: b -> Monad(c) is a little harder:
h: a -> Monad(c) is not just
a => f(g(a)) because f is expecting
b, not Monad(b).
Let’s get a little more concrete and compose a pair of asynchronous functions that each return a promise:
{
const label = 'Promise composition'; const g = n => Promise.resolve(n + 1);
const f = n => Promise.resolve(n * 2); const h = composePromises(f, g); h(20)
.then(trace(label))
;
// Promise composition: 42
}How do we write composePromises() so that the result is
logged correctly? Hint: You’ve already seen it.
Remember our composeMap() function? All you need to do
is change the .map() call to .then().
Promise.then() is basically an
asynchronous .map().
{
const composePromises = (...ms) => (
ms.reduce((f, g) => x => g(x).then(f))
); const label = 'Promise composition'; const g = n => Promise.resolve(n + 1);
const f = n => Promise.resolve(n * 2); const h = composePromises(f, g); h(20)
.then(trace(label))
;
// Promise composition: 42
}The weird part is that when you hit the second function,
f (remember, f after g),
the input value is a promise. It’s not type b, it’s type
Promise(b), but f takes type b,
unwrapped. So what’s going on?
Inside .then(), there’s an unwrapping process that goes
from Promise(b) -> b. That operation is called
join or flatten.
You may have noticed that composeMap() and
composePromises() are almost identical functions. This is
the perfect use-case for a higher-order function that can handle both.
Let’s just mix the chain method into a curried function, then use square
bracket notation:
const composeM = method => (...ms) => (
ms.reduce((f, g) => x => g(x)[method](f))
);Now we can write the specialized implementations like this:
const composePromises = composeM('then');
const composeMap = composeM('map');
const composeFlatMap = composeM('flatMap');Before you can start building your own monads, you need to know there are three laws that all monads should satisfy:
unit(x).chain(f) ==== f(x)m.chain(unit) ==== mm.chain(f).chain(g) ==== m.chain(x => f(x).chain(g))
A monad is a functor. A functor is a morphism between categories,
A -> B. The morphism is represented by an arrow. In
addition to the arrow we explicitly see between objects, each object in
a category also has an arrow back to itself. In other words, for every
object X in a category, there exists an arrow
X -> X. That arrow is known as the identity arrow, and
it’s usually drawn as a little circular arrow pointing from an object
and looping back to the same object.
Associativity just means that it doesn’t matter where we put the
parenthesis when we compose. For example, if you’re adding,
a + (b + c) is the same as (a + b) + c. The
same holds true for function composition:
(f ∘ g) ∘ h = f ∘ (g ∘ h).
The same holds true for Kleisli composition. You just have to read it
backwards. When you see the composition operator (chain),
think after:
h(x).chain(x => g(x).chain(f)) ==== (h(x).chain(g)).chain(f)Let’s prove that the identity monad satisfies the monad laws:
{ // Identity monad
const Id = value => ({
// Functor mapping
// Preserve the wrapping for .map() by
// passing the mapped value into the type
// lift:
map: f => Id.of(f(value)), // Monad chaining
// Discard one level of wrapping
// by omitting the .of() type lift:
chain: f => f(value), // Just a convenient way to inspect
// the values:
toString: () => `Id(${ value })`
}); // The type lift for this monad is just
// a reference to the factory.
Id.of = Id; const g = n => Id(n + 1);
const f = n => Id(n * 2); // Left identity
// unit(x).chain(f) ==== f(x)
trace('Id monad left identity')([
Id(x).chain(f),
f(x)
]);
// Id monad left identity: Id(40), Id(40) // Right identity
// m.chain(unit) ==== m
trace('Id monad right identity')([
Id(x).chain(Id.of),
Id(x)
]);
// Id monad right identity: Id(20), Id(20) // Associativity
// m.chain(f).chain(g) ====
// m.chain(x => f(x).chain(g)
trace('Id monad associativity')([
Id(x).chain(g).chain(f),
Id(x).chain(x => g(x).chain(f))
]);
// Id monad associativity: Id(42), Id(42)
}Monads are a way to compose type lifting functions:
g: a => M(b), f: b => M(c). To
accomplish this, monads must flatten M(b) to b
before applying f(). In other words, functors are things
you can map over. Monads are things you can flatMap over:
a => bFunctor(a) => Functor(b)Monad(Monad(a)) => Monad(b)A monad is based on a simple symmetry — A way to wrap a value into a context, and a way to unwrap the value from the context:
a => M(a)M(a) => aAnd since monads are also functors, they can also map:
M(a) -> M(b)Combine flatten with map, and you get chain — function composition for lifting functions, aka Kleisli composition:
M(M(a)) => M(b)Monads must satisfy three laws (axioms), collectively known as the monad laws:
unit(x).chain(f) ==== f(x)m.chain(unit) ==== mm.chain(f).chain(g) ==== m.chain(x => f(x).chain(g)Examples of monads you might encounter in every day JavaScript code
include promises and observables. Kleisli composition allows you to
compose your data flow logic without worrying about the particulars of
the data type’s API, and without worrying about the possible
side-effects, conditional branching, or other details of the unwrapping
computations hidden in the chain()operation.
This makes monads a very powerful tool to simplify your code. You don’t have to understand or worry about what’s going on inside monads to reap the simplifying benefits that monads can provide, but now that you know more about what’s under the hood, taking a peek under the hood isn’t such a scary prospect.
No need to fear Lady Monadgreen’s curse.
One of the biggest complaints I hear about TDD and unit tests is that people struggle with all of the mocking required to isolate units. Some people struggle to understand how their unit tests are even meaningful. In fact, I’ve seen developers get so lost in mocks, fakes, and stubs that they wrote entire files of unit tests where no actual implementation code was exercised at all. Oops.
On the other end of the spectrum, it’s common to see developers get so sucked into the dogma of TDD that they think they absolutely must achieve 100% code coverage, by any means necessary, even if that means they have to make their codebase more complex to pull it off.
I frequently tell people that mocking is a code smell, but most developers pass through a stage in their TDD skills where they want to achieve 100% unit test coverage, and can’t imagine a world in which they do not use mocks extensively. In order to squeeze mocks into their application, they tend to wrap dependency injection functions around their units or (worse), pack services into dependency injection containers.
Angular takes this to an extreme by baking dependency injection right into all Angular component classes, tempting users to view dependency injection as the primary means of decoupling. But dependency injection is not the best way to accomplish decoupling.
The process of learning effective TDD is the process of learning how to build more modular applications.
TDD tends to have a simplifying effect on code, not a complicating effect. If you find that your code gets harder to read or maintain when you make it more testable, or you have to bloat your code with dependency injection boilerplate, you’re doing TDD wrong.
Don’t waste your time wedging dependency injection into your app so you can mock the whole world. Chances are very good that it’s hurting you more than it’s helping. Writing more testable code should simplify your code. It should require fewer lines of code and more readable, flexible, maintainable constructions. Dependency injection has the opposite effect.
This text exists to teach you two things:
More complex code is often accompanied by more cluttered code. You want to produce uncluttered code for the same reasons you want to keep your house tidy:
“A code smell is a surface indication that usually corresponds to a deeper problem in the system.” ~ Martin Fowler
A code smell does not mean that something is definitely wrong, or that something must be fixed right away. It is a rule of thumb that should alert you to a possible opportunity to improve something.
This text and its title in no way imply that all mocking is bad, or that you should never mock anything.
Additionally, different types of code need different levels (and different kinds) of mocks. Some code exists primarily to facilitate I/O, in which case, there is little to do other than test I/O, and reducing mocks might mean your unit test coverage would be close to 0.
If there is no logic in your code (just pipes and pure compositions), 0% unit test coverage might be acceptable, assuming your integration or functional test coverage is close to 100%. However, if there is logic (conditional expressions, assignments to variables, explicit function calls to units, etc…), you probably do need unit test coverage, and there may be opportunities to simplify your code and reduce mocking requirements.
A mock is a test double that stands in for real implementation code during the unit testing process. A mock is capable of producing assertions about how it was manipulated by the test subject during the test run. If your test double produces assertions, it’s a mock in the specific sense of the word.
The term “mock” is also used more generally to refer to the use of any kind of test double. For the purpose of this text, we’ll use the words “mock” and “test double” interchangeably to match popular usage. All test doubles (dummies, spies, fakes, etc…) stand in for real code that the test subject is tightly coupled to, therefore, all test doubles are an indication of coupling, and there may be an opportunity to simplify the implementation and improve the quality of the code under test. At the same time, eliminating the need for mocking can radically simplify the tests themselves, because you won’t have to construct the mocks.
Unit tests test individual units (modules, functions, classes) in isolation from the rest of the program.
Contrast unit tests with integration tests, which test integrations between two or more units, and functional tests, which test the application from the point of view of the user, including complete user interaction workflows from simulated UI manipulation, to data layer updates, and back to the user output (e.g., the on-screen representation of the app). Functional tests are a subset of integration tests, because they test all of the units of an application, integrated in the context of the running application.
In general, units are tested using only the public interface of the unit (aka “public API” or “surface area”). This is referred to as black box testing. Black box testing leads to less brittle tests, because the implementation details of a unit tend to change more over time than the public API of the unit. If you use white box testing, where tests are aware of implementation details, any change to the implementation details could break the test, even if the public API continues to function as expected. In other words, white-box testing leads to wasted rework.
Code coverage refers to the amount of code covered by test cases. Coverage reports can be created by instrumenting the code and recording which lines were exercised during a test run. In general, we try to produce a high level of coverage, but code coverage starts to deliver diminishing returns as it gets closer to 100%.
In my experience, increasing coverage beyond ~90% seems to have little continued correlation with lower bug density.
Why would that be? Doesn’t 100% tested code mean that we know with 100% certainty that the code does what it was designed to do?
It turns out, it’s not that simple.
What most people don’t realize is that there are two kinds of coverage:
Case coverage refers to use-case scenarios: How the code will behave in the context of real world environment, with real users, real networks, and even hackers intentionally trying to subvert the design of the software for nefarious purposes.
Coverage reports identify code-coverage weaknesses, not case-coverage weaknesses. The same code may apply to more than one use-case, and a single use-case may depend on code outside the subject-under-test, or even in a separate application or 3rd party API.
Because use-cases may involve the environment, multiple units, users, and networking conditions, it is impossible to cover all required use-cases with a test suite that only contains unit tests. Unit tests by definition test units in isolation, not in integration, meaning that a test suite containing only unit tests will always have close to 0% case coverage for integration and functional use-case scenarios.
100% code coverage does not guarantee 100% case coverage.
Developers targeting 100% code coverage are chasing the wrong metric.
The need to mock in order to achieve unit isolation for the purpose of unit tests is caused by coupling between units. Tight coupling makes code more rigid and brittle: more likely to break when changes are required. In general, less coupling is desirable for its own sake because it makes code easier to extend and maintain. The fact that it also makes testing easier by eliminating the need for mocks is just icing on the cake.
From this we can deduce that if we’re mocking something, there may be an opportunity to make our code more flexible by reducing the coupling between units. Once that’s done, you won’t need the mocks anymore.
Coupling is the degree to which a unit of code (module, function, class, etc…) depends upon other units of code. Tight coupling, or a high degree of coupling, refers to how likely a unit is to break when changes are made to its dependencies. In other words, the tighter the coupling, the harder it is to maintain or extend the application. Loose coupling reduces the complexity of fixing bugs and adapting the application to new use-cases.
Coupling takes different forms:
Tight coupling has many causes:
Imperative and object-oriented code is more susceptible to tight coupling than functional code. That doesn’t mean that programming in a functional style makes your code immune to tight coupling, but functional code uses pure functions as the elemental unit of composition, and pure functions are less vulnerable to tight coupling by nature.
Pure functions:
How do pure functions reduce coupling?
Everything. The essence of all software development is the process of breaking a large problem down into smaller, independent pieces (decomposition) and composing the solutions together to form an application that solves the large problem (composition).
Mocking is required when our decomposition strategy has failed.
Mocking is required when the units used to break the large problem down into smaller parts depend on each other. Put another way, mocking is required when our supposed atomic units of composition are not really atomic, and our decomposition strategy has failed to decompose the larger problem into smaller, independent problems.
When decomposition succeeds, it’s possible to use a generic composition utility to compose the pieces back together. Examples:
lodash/fp/composeasyncPipe(), Kleisli composition with
composeM(), composeK(), etc…When you use generic composition utilities, each element of the composition can be unit tested in isolation without mocking the others.
The compositions themselves will be declarative, so they’ll contain zero unit-testable logic (presumably the composition utility is a third party library with its own unit tests).
Under those circumstances, there’s nothing meaningful to unit test. You need integration tests, instead.
Let’s contrast imperative vs declarative composition using a familiar example:
// Function composition OR
// import pipe from 'lodash/fp/flow';
const pipe = (...fns) => x => fns.reduce((y, f) => f(y), x);// Functions to compose
const g = n => n + 1;
const f = n => n * 2;// Imperative composition
const doStuffBadly = x => {
const afterG = g(x);
const afterF = f(afterG);
return afterF;
};// Declarative composition
const doStuffBetter = pipe(g, f);console.log(
doStuffBadly(20), // 42
doStuffBetter(20) // 42
);Function composition is the process of applying a function to the return value of another function. In other words, you create a pipeline of functions, then pass a value to the pipeline, and the value will go through each function like a stage in an assembly line, transforming the value in some way before it’s passed to the next function in the pipeline. Eventually, the last function in the pipeline returns the final value.
initialValue -> [g] -> [f] -> resultIt is the primary means of organizing application code in every mainstream language, regardless of paradigm. Even Java uses functions (methods) as the primary message passing mechanism between different class instances.
You can compose functions manually (imperatively), or automatically (declaratively). In languages without first-class functions, you don’t have much choice. You’re stuck with imperative. In JavaScript (and almost all the other major popular languages), you can do it better with declarative composition.
Imperative style means that we’re commanding the computer to do something step-by-step. It’s a how-to guide. In the example above, the imperative style says:
xafterG and assign the result of
g(x) to itafterF and assign the result of
f(afterG) to itafterF.The imperative style version requires logic that should be tested. I know those are just simple assignments, but I’ve frequently seen (and written) bugs where I pass or return the wrong variable.
Declarative style means we’re telling the computer the relationships between things. It’s a description of structure using equational reasoning. The declarative example says:
doStuffBetter is the piped composition of
g and f.That’s it.
Assuming f and g have their own unit tests,
and pipe() has its own unit tests (use flow()
from Lodash or pipe() from Ramda, and it will), there’s no
new logic here to unit test.
In order for this style to work correctly, the units we compose need to be decoupled.
To remove coupling, we first need a better understanding of where coupling dependencies come from. Here are the main sources, roughly in order of how tight the coupling is:
Tight coupling:
const enhancedWidgetFactory = compose(eventEmitter, widgetFactory, enhancements);
where widgetFactory depends on
eventEmitterLoose coupling:
Ironically, most of the sources of coupling are mechanisms originally designed to reduce coupling. That makes sense, because in order to recompose our smaller problem solutions into a complete application, they need to integrate and communicate somehow. There are good ways, and bad ways. The sources that cause tight coupling should be avoided whenever it’s practical to do so. The loose coupling options are generally desirable in a healthy application.
You might be confused that I classified dependency injection containers and dependency injection parameters in the “tight coupling” group, when so many books and blog post categorize them as “loose coupling”. Coupling is not binary. It’s a gradient scale. That means that any grouping is going to be somewhat subjective and arbitrary.
I draw the line with a simple, objective litmus test:
Can the unit be tested without mocking dependencies? If it can’t, it’s tightly coupled to the mocked dependencies.
The more dependencies your unit has, the more likely it is that there may be problematic coupling. Now that we understand how coupling happens, what can we do about it?
That means that the code you use to set up network requests and request handlers won’t need unit tests. Use integration tests for those, instead.
That bears repeating:
Don’t unit test I/O.
I/O is for integrations. Use integration tests, instead.
It’s perfectly OK to mock and fake for integration tests.
Using pure functions takes a little practice, and without that practice, it’s not always clear how to write a pure function to do what you want to do. Pure functions can’t directly mutate global variables, the arguments passed into them, the network, the disk, or the screen. All they can do is return a value.
If you’re passed an array or an object, and you want to return a
changed version of that object, you can’t just make the changes to the
object and return it. You have to create a new copy of the object with
the required changes. You can do that with the array accessor
methods (not the mutator methods),
Object.assign(), using a new empty object as the target, or
the array or object spread syntax. For example:
// Not pure
const signInUser = user => user.isSignedIn = true;const foo = {
name: 'Foo',
isSignedIn: false
};// Foo was mutated
console.log(
signInUser(foo), // true
foo // { name: "Foo", isSignedIn: true }
);vs…
// Pure
const signInUser = user => ({...user, isSignedIn: true });const foo = {
name: 'Foo',
isSignedIn: false
};// Foo was not mutated
console.log(
signInUser(foo), // { name: "Foo", isSignedIn: true }
foo // { name: "Foo", isSignedIn: false }
);Alternatively, you can try a library for immutable data types, such as Mori or Immutable.js. I’m hopeful that we’ll someday get a nice set of immutable datatypes similar to Clojure’s in JavaScript, but I’m not holding my breath.
You may think that returning new objects could cause a performance
hit because we’re creating a new object instead of reusing the existing
ones, but a fortunate side-effect of that is that we can detect changes
to objects by using an identity comparison (=== check), so
we don’t have to traverse through the entire object to discover if
anything has changed.
You can use that trick to make React components render faster if you
have a complex state tree that you may not need to traverse in depth
with each render pass. Inherit from PureComponent and it
implements shouldComponentUpdate() with a shallow prop and
state comparison. When it detects identity equality, it knows that
nothing has changed in that part of the state tree and it can move on
without a deep state traversal.
Pure functions can also be memoized, meaning that you don’t have to build the whole object again if you’ve seen the same inputs before. You can trade computation complexity for memory and store pre-calculated values in a lookup table. For computationally expensive processes which don’t require unbounded memory, this may be a great optimization strategy.
Another property of pure functions is that, because they have no side-effects, it’s safe to distribute complex computations over large clusters of processors, using a divide-and-conquer strategy. This tactic is often employed to process images, videos, or audio frames using massively parallel GPUs originally designed for graphics, but now commonly used for lots of other purposes, like scientific computing.
In other words, mutation isn’t always faster, and it is often orders of magnitude slower because it takes a micro-optimization at the expense of macro-optimizations.
There are several strategies that can help you isolate side-effects from the rest of your program logic. Here are some of them:
asyncPipe().call() from redux-saga doesn’t
actually call a function. Instead, it returns an object with a reference
to a function and its arguments, and the saga middleware calls it for
you. That makes call() and all the functions that use it
pure functions, which are easy to unit test with no mocking
required.Pub/sub is short for the publish/subscribe pattern. In the publish/subscribe pattern, units don’t directly call each other. Instead, they publish messages that other units (subscribers) can listen to. Publishers don’t know what (if any) units will subscribe, and subscribers don’t know what (if any) publishers will publish.
Pub/sub is baked into the Document Object Model (DOM). Any component in your application can listen to events dispatched from DOM elements, such as mouse movements, clicks, scroll events, keystrokes, and so on. Back when everyone built web apps with jQuery, it was common to jQuery custom events to turn the DOM into a pub/sub event bus to decouple view rendering concerns from state logic.
Pub/sub is also baked into Redux. In Redux, you create a global model
for application state (called the store). Instead of directly
manipulating models, views and I/O handlers dispatch action objects to
the store. An action object has a special key, called type
which various reducers can listen for and respond to. Additionally,
Redux supports middleware, which can also listen for and respond to
specific action types. This way, your views don’t need to know anything
about how your application state is handled, and the state logic doesn’t
need to know anything about the views.
It also makes it trivial to patch into the dispatcher via middleware and trigger cross-cutting concerns, such as action logging/analytics, syncing state with storage or the server, and patching in realtime communication features with servers and network peers.
Sometimes you can use monad compositions (like promises) to eliminate dependent logic from your compositions. For example, the following function contains logic that you can’t unit test without mocking all of the async functions:
async function uploadFiles({user, folder, files}) {
const dbUser = await readUser(user);
const folderInfo = await getFolderInfo(folder);
if (await haveWriteAccess({dbUser, folderInfo})) {
return uploadToFolder({dbUser, folderInfo, files });
} else {
throw new Error("No write access to that folder");
}
}Let’s throw in some helper pseudo-code to make it runnable:
const log = (...args) => console.log(...args);// Ignore these. In your real code you'd import
// the real things.
const readUser = () => Promise.resolve(true);
const getFolderInfo = () => Promise.resolve(true);
const haveWriteAccess = () => Promise.resolve(true);
const uploadToFolder = () => Promise.resolve('Success!');// gibberish starting variables
const user = '123';
const folder = '456';
const files = ['a', 'b', 'c'];async function uploadFiles({user, folder, files}) {
const dbUser = await readUser({ user });
const folderInfo = await getFolderInfo({ folder });
if (await haveWriteAccess({dbUser, folderInfo})) {
return uploadToFolder({dbUser, folderInfo, files });
} else {
throw new Error("No write access to that folder");
}
}uploadFiles({user, folder, files})
.then(log)
;And now refactor it to use promise composition via
asyncPipe():
const asyncPipe = (...fns) => x => (
fns.reduce(async (y, f) => f(await y), x)
);const uploadFiles = asyncPipe(
readUser,
getFolderInfo,
haveWriteAccess,
uploadToFolder
);uploadFiles({user, folder, files})
.then(log)
;The conditional logic is easily removed because promises have conditional branching built-in. The idea is that logic and I/O don’t mix well, so we want to remove the logic from the I/O dependent code.
In order to make this kind of composition work, we need to ensure 2 things:
haveWriteAccess() will reject if the user doesn’t have
write access. That moves the conditional logic into the promise context
so we don’t have to unit test it or worry about it at all (promises have
their own tests baked into the JS engine code).pipelineData type for this composition
which is just an object containing the following keys:
{ user, folder, files, dbUser?, folderInfo? }. This creates
a structure sharing dependency between the components, but you can use
more generic versions of these functions in other places and specialize
them for this pipeline with thin wrapping functions.With those conditions met, it’s trivial to test each of these functions in isolation from each other without mocking the other functions. Since we’ve extracted all of the logic out of the pipeline, there’s nothing meaningful left to unit test in this file. All that’s left to test are the integrations.
Remember: Logic and I/O are separate concerns.
Logic is thinking. Effects are actions. Think before you act!
The strategy used by redux-saga is to use objects that represent future computations. The idea is similar to returning a monad, except that it doesn’t always have to be a monad that gets returned. Monads are capable of composing functions with the chain operation, but you can manually chain functions using imperative-style code, instead. Here’s a rough sketch of how redux-saga does it:
// sugar for console.log we'll use later
const log = msg => console.log(msg);const call = (fn, ...args) => ({ fn, args });
const put = (msg) => ({ msg });// imported from I/O API
const sendMessage = msg => Promise.resolve('some response');// imported from state handler/Reducer
const handleResponse = response => ({
type: 'RECEIVED_RESPONSE',
payload: response
});const handleError = err => ({
type: 'IO_ERROR',
payload: err
});function* sendMessageSaga (msg) {
try {
const response = yield call(sendMessage, msg);
yield put(handleResponse(response));
} catch (err) {
yield put(handleError(err));
}
}You can see all the calls being made in your unit tests without mocking the network API or invoking any side-effects. Bonus: This makes your application extremely easy to debug without worrying about nondeterministic network state, etc…
Want to simulate what happens in your app when a network error
occurs? Simply call iter.throw(NetworkError)
Elsewhere, some library middleware is driving the function, and actually triggering the side-effects in the production application:
const iter = sendMessageSaga('Hello, world!');// Returns an object representing the status and value:
const step1 = iter.next();log(step1);
/* =>
{
done: false,
value: {
fn: sendMessage
args: ["Hello, world!"]
}
}
*/Destructure the call() object from the yielded value to
inspect or invoke the future computation:
const { value: {fn, args }} = step1;Effects run in the real middleware. You can skip this part when you’re testing and debugging.
const step2 = fn(args);step2.then(log); // "some response"If you want to simulate a network response without mocking APIs or
the http calls, you can pass a simulated response
into .next():
iter.next(simulatedNetworkResponse);From there you can keep calling .next() until
done is true, and your function is finished
running.
Using generators and representations of computations in your unit
tests, you can simulate everything up to but excluding invoking
the real side-effects. You can pass values into .next()
calls to fake responses, or throw errors at the iterator to fake errors
and promise rejections.
Using this style, there’s no need to mock anything in unit tests, even for complex integrational workflows with lots of side-effects.
All this stuff about using better architecture is great, but in the real world, we have to use other people’s APIs, and integrate with legacy code, and there are lots of APIs that aren’t pure. Isolated test doubles may be useful in those cases. For example, express passes shared mutable state and models side-effects via continuation passing.
Let’s look at a common example. People try to tell me that the express server definition file needs dependency injection because how else will you unit test all the stuff that goes into the express app? E.g.:
const express = require('express');
const app = express();app.get('/', function (req, res) {
res.send('Hello World!')
});app.listen(3000, function () {
console.log('Example app listening on port 3000!')
});In order to “unit test” this file, we’d have to work up a
dependency injection solution and then pass mocks for everything into it
(possibly including express() itself). If this was a very
complex file where different request handlers were using different
features of express, and counting on that logic to be there, you’d
probably have to come up with a pretty sophisticated fake to make that
work. I’ve seen developers create elaborate fakes and mocks of things
like express, the session middleware, log handlers, realtime network
protocols, you name it. I’ve faced hard mocking questions myself, but
the correct answer is simple.
This file doesn’t need unit tests.
The server definition file for an express app is by definition the app’s main integration point. Testing an express app file is by definition testing an integration between your program logic, express, and all the handlers for that express app. You absolutely should not skip integration tests even if you can achieve 100% unit test coverage.
Instead of trying to unit test this file, isolate your program logic into separate units, and unit test those files. Write real integration tests for the server file, meaning you’ll actually hit the network, or at least create the actual http messages, complete with headers using a tool like supertest.
Let’s refactor the Hello World express example to make it more testable:
Pull the hello handler into its own file and write unit
tests for it. No need to mock the rest of the app components. This
obviously isn’t a pure function, so we’ll need to spy or mock the
response object to make sure we call .send().
const hello = (req, res) => res.send('Hello World!');You could test it something like this. Swap out the if
statement for your favorite test framework expectation:
{
const expected = 'Hello World!';
const msg = `should call .send() with ${ expected }`; const res = {
send: (actual) => {
if (actual !== expected) {
throw new Error(`NOT OK ${ msg }`);
}
console.log(`OK: ${ msg }`);
}
} hello({}, res);
}Pull the listen handler into its own file and write unit tests for it, too. We have the same problem here. Express handlers are not pure, so we need to spy on the logger to make sure it gets called. Testing is similar to the previous example:
const handleListen = (log, port) => () => log(`Example app listening on port ${ port }!`);All that’s left in the server file now is integration logic:
const express = require('express');const hello = require('./hello.js');
const handleListen = require('./handleListen');
const log = require('./log');const port = 3000;
const app = express();app.get('/', hello);app.listen(port, handleListen(port, log));You still need integration tests for this file, but further unit
tests won’t meaningfully enhance your case coverage. We use some very
minimal dependency injection to pass a logger into
handleListen(), but there is certainly no need for any
dependency injection framework for express apps.
Because integration tests test collaborative integrations between units, it’s perfectly OK to fake servers, network protocols, network messages, and so on in order to reproduce all the various conditions you’ll encounter during communication with other units, potentially distributed across clusters of CPUs or separate machines on a network.
Sometimes you’ll want to test how your unit will communicate with a 3rd party API, and sometimes those API’s are prohibitively expensive to test for real. You can record real workflow transactions against the real services and replay them from a fake server to test how well your unit integrates with a third party service actually running in a separate network process. Often this is the best way to test things like “did we see the correct message headers?”
There are lots of useful integration testing tools that throttle network bandwidth, introduce network lag, produce network errors, and otherwise test lots of other conditions that are impossible to test using unit tests which mock away the communication layer.
It’s impossible to achieve 100% case coverage without integration tests. Don’t skip them even if you manage to achieve 100% unit test coverage. Sometimes 100% is not 100%.
“Object Composition Assembling or composing objects to get more complex behavior.” ~ Gang of Four, “Design Patterns: Elements of Reusable Object-Oriented Software”
“Favor object composition over class inheritance.” ~ Gang of Four, “Design Patterns”.
One of the most common mistakes in software development is the tendency to overuse class inheritance. Class inheritance is a code reuse mechanism where instances form is-a relations with base classes. If you’re tempted to model your domain using is-a relations (e.g., a duck is-a bird) you’re bound for trouble, because class inheritance is the tightest form of coupling available in object-oriented design, which leads to many common problems, including (among others):
Class inheritance accomplishes reuse by abstracting a common interface away into a base class that subclasses can inherit from, add to, and override. There are two important parts of abstraction:
There are lots of ways to accomplish generalization and specialization in code. Some good alternatives to class inheritance include simple functions, higher order functions, and object composition.
Unfortunately, object composition is very misunderstood, and many people struggle to think in terms of object composition. It’s time to explore the topic in a bit more depth.
“In computer science, a composite data type or compound data type is any data type which can be constructed in a program using the programming language’s primitive data types and other composite types. […] The act of constructing a composite type is known as composition.” ~ Wikipedia
One of the reasons for the confusion surrounding object composition is that any assembly of primitive types to form a composite object is a form of object composition, but inheritance techniques are often discussed in contrast to object composition as if they are different things. The reason for the dual meaning is that there is a difference between the grammar and semantics of object composition.
When discussing object composition vs class inheritance, we’re not talking about specific techniques: We’re talking about the semantic relationships and degree of coupling between the component objects. We’re talking about meaning as opposed to grammar. People often fail to make the distinction and get mired in the grammar details. They can’t see the forest for the trees.
There are many different ways to compose objects. Different forms of composition will produce different composite structures and different relationships between the objects. When objects depend on the objects they’re related to, those objects are coupled, meaning that changing one object could break the other.
The Gang of Four advice to “favor object composition over class inheritance” invites us to think of our objects as a composition of smaller, loosely coupled objects rather than wholesale inheritance from a monolithic base class. The GoF describes tightly coupled objects as “monolithic systems, where you can’t change or remove a class without understanding and changing many other classes. The system becomes a dense mass that’s hard to learn, port, and maintain.”
In “Design Patterns”, the Gang of Four states, “you’ll see object composition applied again and again in design patterns”, and goes on to describe various types of compositional relationships, including aggregation and delegation.
The authors of “Design Patterns” were primarily working with C++ and Smalltalk (later Java). Building and changing object relations at runtime in those languages is a lot more complicated than it is in JavaScript, so they understandably did not include many details on the subject. However, no discussion of object composition in JavaScript would be complete without a discussion of dynamic object extension, aka concatenation.
For reasons of applicability to JavaScript and to form cleaner generalizations, we’ll diverge slightly from the definitions used in “Design Patterns”. For instance, we won’t require that aggregations imply control over subobject lifecycles. That simply isn’t true in a language with dynamic object extension.
Selecting the wrong axioms can unnecessarily restrict a useful generalization, and force us to come up with another name for a special case of the same general idea. Software developers don’t like to repeat ourselves when we don’t need to.
jQuery.fn.Array.prototype,
objects to Object.prototype, etc…It’s important to note that these different forms of composition are
not mutually exclusive. It’s possible to implement
delegation using aggregation, and class inheritance is implemented using
delegation in JavaScript. Many software systems use more than one type
of composition, e.g., jQuery’s plugins use concatenation to extend the
jQuery delegate prototype, jQuery.fn. When client code
calls a plugin method, the request is delegated to the method that was
concatenated to the delegate prototype.
Note on code examples The code examples below will share the following setup code:
const objs = [
{ a: 'a', b: 'ab' },
{ b: 'b' },
{ c: 'c', b: 'cb' }
];Aggregation is when an object is formed from an enumerable collection of subobjects. An aggregate is an object which contains other objects. Each subobject in an aggregation retains its own reference identity, and could be losslessly destructured from the aggregate. Aggregates can be represented in a wide variety of structures.
Whenever there are collections of objects which need to share common operations, such as iterables, stacks, queues, trees, graphs, state machines, or the composite pattern (when you want a single item to share the same interface as many items).
Aggregations are great for applying universal abstractions, such as
applying a function to each member of an aggregate (e.g.,
array.map(fn)), transforming vectors as if they’re single
values, and so on. If there are potentially hundreds of thousands or
millions of subobjects, however, stream processing may be more
efficient.
Array aggregation:
const collection = (a, e) => a.concat([e]);const a = objs.reduce(collection, []);console.log(
'collection aggregation',
a,
a[1].b,
a[2].c,
`enumerable keys: ${ Object.keys(a) }`
);This will produce:
collection aggregation
[{"a":"a","b":"ab"},{"b":"b"},{"c":"c","b":"cb"}]
b c
enumerable keys: 0,1,2Linked list aggregation using pairs:
const pair = (a, b) => [b, a];const l = objs.reduceRight(pair, []);console.log(
'linked list aggregation',
l,
`enumerable keys: ${ Object.keys(l) }`
);/*
linked list aggregation
[
{"a":"a","b":"ab"}, [
{"b":"b"}, [
{"c":"c","b":"cb"},
[]
]
]
]
enumerable keys: 0,1
*/Linked lists form the basis of lots of other data structures and aggregations, such as arrays, strings, and various kinds of trees. There are many other possible kinds of aggregation. We won’t cover them all in-depth here.
Concatenation is when an object is formed by adding new properties to an existing object.
jQuery.fn via concatenationWhen to use: Any time it would be useful to progressively assemble data structures at runtime, e.g., merging JSON objects, hydrating application state from multiple sources, creating updates to immutable state (by merging previous state with new data), etc…
const c = objs.reduce(concatenate, {});const concatenate = (a, o) => ({...a, ...o});console.log(
'concatenation',
c,
`enumerable keys: ${ Object.keys(c) }`
);// concatenation { a: 'a', b: 'cb', c: 'c' } enumerable keys: a,b,cDelegation is when an object forwards or delegates to another object.
[].map()
delegates to Array.prototype.map(),
obj.hasOwnProperty() delegates to
Object.prototype.hasOwnProperty() and so on.extends keyword), but is very
rarely actually needed.Object.keys(instanceObj).const delegate = (a, b) => Object.assign(Object.create(a), b);
const d = objs.reduceRight(delegate, {});
console.log(
'delegation',
d,
`enumerable keys: ${ Object.keys(d) }`
);
// delegation { a: 'a', b: 'ab' } enumerable keys: a,b
console.log(d.b, d.c); // ab cWe have learned:
[].map() delegates to
Array.prototype.map()Object.assign(destination, a, b),
{...a, ...b}.These are not the only three kinds of object composition. It’s also possible to form loose, dynamic relationships between objects through acquaintance/association relationships where objects are passed as parameters to other objects (dependency injection), and so on.
All software development is composition. There are easy, flexible ways to compose objects, and brittle, arthritic ways. Some forms of object composition form loosely coupled relations between objects, and others form very tight coupling.
Look for ways to compose where a small change to program requirements would require only a small change to the code implementation. Express your intention clearly and concisely, and remember: If you think you need class inheritance, chances are very good that there’s a better way to do it.
Conventional wisdom would have you believe that nested ternaries are unreadable, and should be avoided.
Conventional wisdom is sometimes unwise.
The truth is, ternaries are usually much simpler than if statements. People believe the reverse for two reasons:
Before we get into the details, let’s define a ternary expression:
A ternary expression is a conditional expression that evaluates to a value. It consists of a conditional, a truthy clause (the value to produce if the conditional evaluates to a truthy value), and a falsy clause (the value to produce if the conditional evaluates to a falsy value).
They look like this:
(conditional)
? truthyClause
: falsyClauseSeveral programming languages (including Smalltalk, Haskell, and most
functional programming languages) don’t have if statements at all. They
have if expressions, instead.
An if expression is a conditional expression that evaluates to a value. It consists of a conditional, a truthy clause (the value to produce if the conditional evaluates to a truthy value), and a falsy clause (the value to produce if the conditional evaluates to a falsy value).
Does that look familiar? Most functional programming languages use
ternary expressions for their if keyword. Why?
An expression is a chunk of code that evaluates to a single value.
A statement is a chunk of code that may not evaluate to a value at all. In JavaScript if statements don’t evaluate to values. In order for an if statement in JavaScript to do anything useful, it must cause a side-effect or return a value from the containing function.
In functional programming, we tend to avoid mutations and
other side-effects. Since if in JavaScript naturally
affords mutation and side effects, many functional programmers
reach for ternaries instead — nested or not. Including me.
Thinking in terms of ternary expressions is a bit different from thinking in terms of if statements, but if you practice a lot for a couple of weeks, you’ll start to gravitate towards ternaries naturally, if only because it’s less typing, as you’ll soon see.
The common claim I hear is that nested ternary expressions are “hard to read”. Let’s shatter that myth with some code examples:
const withIf = ({
conditionA, conditionB
}) => {
if (conditionA) {
if (conditionB) {
return valueA;
}
return valueB;
}
return valueC;
};Note that in this version, there are nesting conditions and braces visually separating the truthy clause from the falsy clauses, making them feel very disconnected. This is fairly simple logic, but it’s a little taxing to parse.
Here’s the same logic written in ternary expression form:
const withTernary = ({
conditionA, conditionB
}) => (
(!conditionA)
? valueC
: (conditionB)
? valueA
: valueB
);There are a few interesting points to be made here:
First, we’ve flattened out the nesting. “Nested” ternaries is a bit of a misnomer, because ternaries are easy to write in a straight line, you never need to nest them with indent levels at all. They simply read top to bottom in a straight line, returning a value as soon as they hit a truthy condition or the fallback.
If you write ternaries properly, there is no nesting to parse. It’s pretty hard to get lost following a straight line.
We should probably call them “chained ternaries” instead.
The second thing I want to point out is that, in order to simplify
this straight line chaining, I switched up the order a little bit: If
you get to the end of a ternary expression and find you need to write
two colon clauses (:), grab the last clause, move it to the
top, and reverse the logic of the first conditional to simplify parsing
the ternary. No more confusion!
It’s worth noting that we can use the same trick to simplify the if statement form:
const withIf = ({
conditionA, conditionB
}) => {
if (!conditionA) return valueC;
if (conditionB) {
return valueA;
}
return valueB;
};That’s better, but it still visually breaks up the related clauses
for conditionB, which can cause confusion. I’ve seen that
problem lead to logic bugs during code maintenance. Even with the logic
flattened, this version is still more cluttered than the ternary
version.
The if version contains a bit more noise: the
if keyword vs ?, return to force
the statement to return a value, extra semicolons, extra braces, etc…
Unlike this example, most if statements also mutate some outside state,
which further adds to the extra code and complexity.
Extra code is bad for a few important reasons. I’ve said all this before but it’s worth repeating until every developer has it burned into their brain:
The average human brain has only a few shared resources for discrete quanta in working memory, and each variable potentially consumes one of those quanta. As you add more variables, your ability to accurately recall the meaning of each variable is diminished. Working memory models typically involve 4–7 discrete quanta. Above those numbers, error rates dramatically increase.
When we force mutation or side-effects with if statements as opposed to ternaries, that often entails adding variables to the mix that don’t need to be there.
Concise code also improves the signal-to-noise ratio of your code. It’s like listening to a radio — when the radio is not tuned properly to the station, you get a lot of interfering noise, and it’s harder to hear the music. When you tune it to the correct station, the noise goes away, and you get a stronger musical signal.
Code is the same way. More concise code expression leads to enhanced comprehension. Some code gives us useful information, and some code just takes up space. If you can reduce the amount of code you use without reducing the meaning that gets transmitted, you’ll make the code easier to parse and understand for other people who need to read it.
Take a look at the before and after functions. It looks like the function went on a diet and lost a ton of weight. That’s important because extra code means extra surface area for bugs to hide in, which means more bugs will hide in it.
Less code = less surface area for bugs = fewer bugs.
Many if statements do more than evaluate to a value. They also cause side-effects, or mutate variables, so you can’t see the complete effect of the if statement without also knowing the impact of those side effects and the full history of everything else that touches its shared mutable state.
Restricting yourself to returning a value forces discipline: severing dependencies so your program is easier to understand, debug, refactor, and maintain.
This is actually my favorite benefit of ternary expressions:
Using ternaries will make you a better developer.
Since all ternaries are easy to arrange in a straight line, top to bottom, calling them “nested ternaries” is a bit of a misnomer. Let’s call them “chained ternaries”, instead.
Chained ternaries have several advantages over if statements: