
Jack Franklin | June 07, 2016
Once your website or application goes past a small number of lines, it will inevitably contain bugs of some sort. This isn’t specific to JavaScript but is shared by nearly all languages—it’s very tricky, if not impossible, to thoroughly rule out the chance of any bugs in your application. However, that doesn’t mean we can’t take precautions by coding in a way that lessens our vulnerability to bugs.
A pure function is defined as one that doesn’t depend on or modify variables outside of its scope. That’s a bit of a mouthful, so let’s dive into some code for a more practical example.
Take this function that calculates whether a user’s mouse is on the left-hand side of a page, and logs true if it is and false otherwise. In reality your function would probably be more complex and do more work, but this example does a great job of demonstrating:
function mouseOnLeftSide(mouseX) {
return mouseX < window.innerWidth / 2;
}
document.onmousemove = function(e) {
console.log(mouseOnLeftSide(e.pageX));
};mouseOnLeftSide() takes an X coordinate and
checks to see if it’s less than half the window width—which would place
it on the left side. However, mouseOnLeftSide() is not a
pure function. We know this because within the body of the function, it
refers to a value that it wasn’t explicitly given:
return mouseX < window.innerWidth / 2;The function is given mouseX, but not window.innerWidth. This means the function is reaching out to access data it wasn’t given, and hence it’s not pure.
You might ask why this is an issue—this piece of code works just fine and does the job expected of it. Imagine that you get a bug report from a user that when the window is less than 500 pixels wide the function is incorrect. How do you test this? You’ve got two options:
Keen to have a test in place to avoid this bug recurring, we pick the second option and get writing. Now we face a new problem, though: how do we set up our test correctly? We know we need to set up our test with the window width set to less than 500 pixels, but how? The function relies on window.innerWidth, and making sure that’s at a particular value is going to be a pain.
With that issue of how to test in mind, imagine we’d instead written the code like so:
function mouseOnLeftSide(mouseX, windowWidth) {
return mouseX < windowWidth / 2;
}
document.onmousemove = function(e) {
console.log(mouseOnLeftSide(e.pageX, window.innerWidth));
};The key difference here is that mouseOnLeftSide() now
takes two arguments: the mouse X position and the window width.
This means that mouseOnLeftSide() is now a pure function;
all the data it needs it is explicitly given as inputs and it never has
to reach out to access any data.
In terms of functionality, it’s identical to our previous example,
but we’ve dramatically improved its maintainability and testability. Now
we don’t have to hack around to fake window.innerWidth for any tests,
but instead just call mouseOnLeftSide() with the exact
arguments we need:
mouseOnLeftSide(5, 499) // ensure it works with width < 500Besides being easier to test, pure functions have other characteristics that make them worth using whenever possible. By their very nature, pure functions are self-documenting. If you know that a function doesn’t reach out of its scope to get data, you know the only data it can possibly touch is passed in as arguments. Consider the following function definition:
function mouseOnLeftSide(mouseX, windowWidth){};You know that this function deals with two pieces of data, and if the arguments are well named it should be clear what they are. We all have to deal with the pain of revisiting code that’s lain untouched for six months, and being able to regain familiarity with it quickly is a key skill.
The problem of global variables is well documented in JavaScript—the language makes it trivial to store data globally where all functions can access it. This is a common source of bugs, too, because anything could have changed the value of a global variable, and hence the function could now behave differently.
An additional property of pure functions is referential transparency.
This is a rather complex term with a simple meaning: given the same
inputs, the output is always the same. Going back to
mouseOnLeftSide, let’s look at the first definition we
had:
function mouseOnLeftSide(mouseX) {
return mouseX < window.innerWidth / 2;
}This function is not referentially transparent. I could call it with the input 5 multiple times, resize the window between calls, and the result would be different every time. This is a slightly contrived example, but functions that return different values even when their inputs are the same are always harder to work with. Reasoning about them is harder because you can’t guarantee their behavior. For the same reason, testing is trickier, because you don’t have full control over the data the function needs.
On the other hand, our improved mouseOnLeftSide function
is referentially transparent because all its data comes from inputs and
it never reaches outside itself:
function mouseOnLeftSide(mouseX, windowWidth) {
return mouseX < windowWidth / 2;
}You get referential transparency for free when following the rule of declaring all your data as inputs, and by doing this you eliminate an entire class of bugs around side effects and functions acting unexpectedly. If you have full control over the data, you can hunt down and replicate bugs much more quickly and reliably without chancing the lottery of global variables that could interfere.
It’s impossible to have pure functions consistently—there will always be a time when you need to reach out and fetch data, the most common example of which is reaching into the DOM to grab a specific element to interact with. It’s a fact of JavaScript that you’ll have to do this, and you shouldn’t feel bad about reaching outside of your function. Instead, carefully consider if there is a way to structure your code so that impure functions can be isolated. Prevent them from having broad effects throughout your codebase, and try to use pure functions whenever appropriate.
Let’s take a look at the code below, which grabs an element from the DOM and changes its background color to red:
function changeElementToRed() {
var foo = document.getElementById('foo');
foo.style.backgroundColor = "red";
}
changeElementToRed();There are two problems with this piece of code, both solvable by transitioning to a pure function:
Given the two points above, I would rewrite this function to:
function changeElementToRed(elem) {
elem.style.backgroundColor = "red";
}
function changeFooToRed() {
var foo = document.getElementById('foo');
changeElementToRed(foo);
}
changeFooToRed();We’ve now changed changeElementToRed() to not be tied to
a specific DOM element and to be more generic. At the same time, we’ve
made it pure, bringing us all the benefits discussed previously.
It’s important to note, though, that I’ve still got some impure
code—changeFooToRed() is impure. You can never avoid this,
but it’s about spotting opportunities where turning a function pure
would increase its readability, reusability, and testability. By keeping
the places where you’re impure to a minimum and creating as many pure,
reusable functions as you can, you’ll save yourself a huge amount of
pain in the future and write better code.
“Pure functions,” “side effects,” and “referential transparency” are terms usually associated with purely functional languages, but that doesn’t mean we can’t take the principles and apply them to our JavaScript, too. By being mindful of these principles and applying them wisely when your code could benefit from them you’ll gain more reliable, self-documenting codebases that are easier to work with and that break less often. I encourage you to keep this in mind next time you’re writing new code, or even revisiting some existing code. It will take some time to get used to these ideas, but soon you’ll find yourself applying them without even thinking about it. Your fellow developers and your future self will thank you.
Inspired by Swift Functors, Applicatives, and Monads in Pictures where the original article Functors, Applicatives, And Monads In Pictures is translated from Haskell into Swift, I would like to write a javascript version for it so that people not familiar with above languages can get the gist of essential functional programming concepts.
Some may feel this is a poor choice as it’s against the common understanding that javascript is predominately imperative. However, according to our respectable javascript guru, Douglas Crockford in JavaScript:
The World’s Most Misunderstood Programming Language. “… This is misleading because JavaScript has more in common with functional languages like Lisp or Scheme than with C or Java. …” I believe javascript is equipped with most of functional programming features and fully capable of writing functional code.
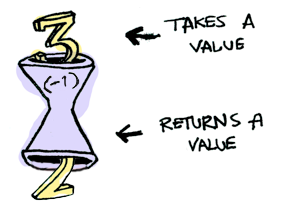
Here’s a simple value:

And we know how to apply a function to this value:
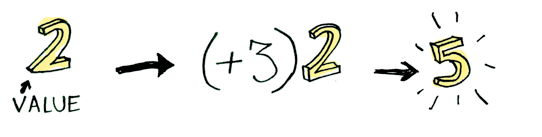
Simple enough. Lets extend this by saying that any value can be in a context. For now you can think of a context as a “box” that you can put a value in:
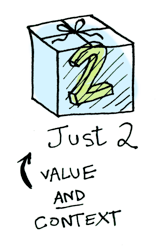
Now when you apply a function to this value, you’ll get different results depending on the containing box. This is the idea that Functors, Applicatives, Monads, Arrows etc are all based on.
In Haskell, Maybe type encapsulates an optional value which is either a value of type a (Just a) or empty (Nothing). It serves as a container referring to the “box” mentioned above where we can put stuff in. In javascript, there is no such thing like Maybe while we can easily see counterparts in other languages, such as Optional in Swift and Java 8, or Option in Scala.
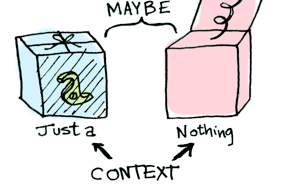
To wrap the value, let’s use Array in javascript to represent a containing box.
When a value is wrapped in a box, you can’t apply a normal function to it:

This is where map (fmap in Haskell) (<$> in Haskell) comes in. map is from the street, map is hip to containing box. map knows how to apply functions to values that are wrapped in a box. For example, suppose you want to apply a function that adds 3 to the wrapped 2 and assume there’s a map function exist:
const plus3 = val => val + 3;
[ 2 ].map( plus3 );
// => [ 5 ]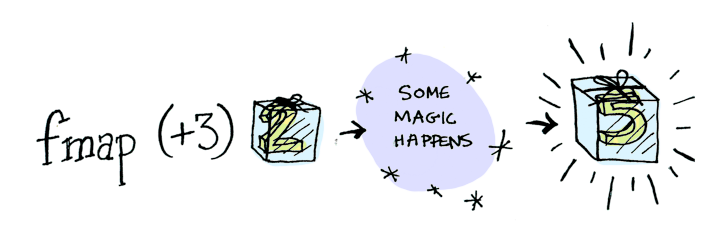
A functor is any type that defines how map (fmap in Haskell) works.
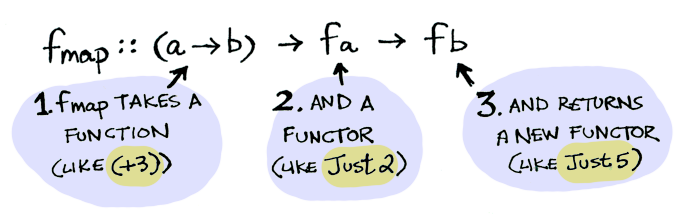
And map magically applies this function because Array is a Functor. map was initially defined in ECMAScript 5. Now it’s widely supported in most of modern browsers and javascript runtimes. Before that, this is how map is implemented in Underscore.js :
_.map = _.collect = function(obj, iteratee, context) {
iteratee = cb(iteratee, context);
var keys = !isArrayLike(obj) && _.keys(obj),
length = (keys || obj).length,
results = Array(length);
for (var index = 0; index < length; index++) {
var currentKey = keys ? keys[index] : index;
results[index] = iteratee(obj[currentKey], currentKey, obj);
}
return results;
};Regardless it iterates each values, here’s what is happening behind the scenes when we write [2].map(plus3):
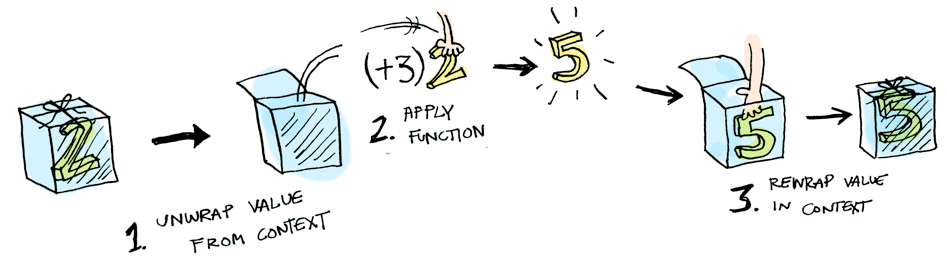
So then you’re like, alright map, please apply plusThree to a empty container.
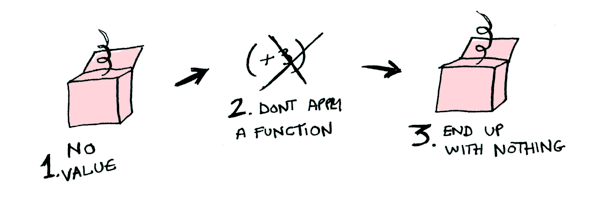
[].map(plus3);
//=> []It does end up with nothing. To illustrate it doesn’t apply a function at all, we tweak the function a bit:
var plus3AndPrintValue = function(val) {
var result = val + 3;
console.log(result);
return result;
}
[2].map(plus3AndPrintValue);
// '5'
[].map(plus3AndPrintValue);
// nothing
Like Morpheus in the Matrix, map knows just what to do; you start with None, and you end up with None! map is zen.
In javascript, Promise should be also considered a container that encapsulates eventual result of an asynchronous operation. It uses then function to interact with the yielded value based on its states:
var promise = Promise.resolve(1); //Wrapped value 1
promise.then(function(value) {
return value + 1; // Success!
}, function(reason) {
console.log(reason); // Error!
});In this case, Promise is also a functor. It has an interface where we can apply a function to its wrapped value.
Here’s another example: what happens when you apply a function to a list?
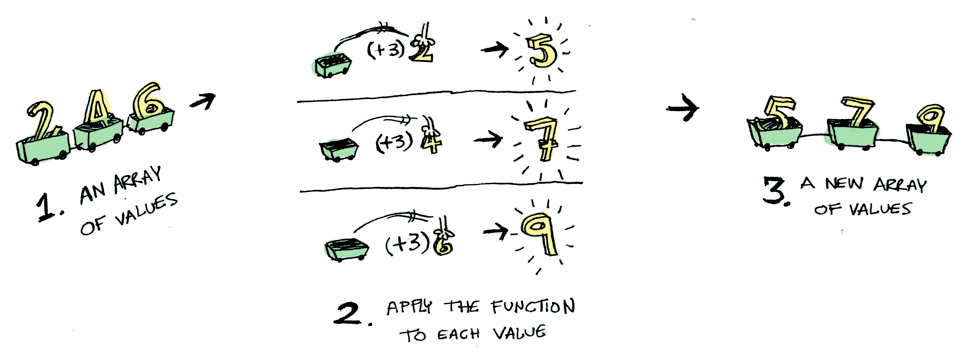
When an Array has multiple values, it naturally applies the function to each value and replaces the array with new values.
Okay, okay, one last example: what happens when you apply a function to another function?
Here’s a function:
Here’s a function applied to another function:
The result is just another function! In javascript, we can achieve that by doing function composition:
var plus2 = function(val) {
return val + 2;
}
var plus3 = function(val) {
return val + 3;
}
var compose = function(f, g) {
//return a composed function
return function(x) {
return f(g(x));
};
};
compose(plusThree, plusTwo)(10);
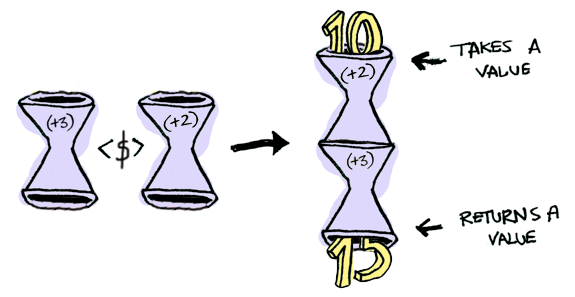
// "15"Applicatives take it to the next level. With an applicative, our values are wrapped in a container, just like Functors:
But our functions are wrapped in a container too!

Yeah. Let that sink in. Applicatives don’t kid around. Unlike Haskell, javascript doesn’t have a built-in way to deal with Applicative.
Says we have two wrapped values and we want to add them up:
//Wrapped values
var wrapped2 = [2];
var wrapped3 = [3];
//Won't work ! The values are wrapped.
add(wrapped2, wrapped3);What if we put a curried add function in map if the container is a functor ?
//If add can be curried
var wrappedPlus3 = wrapped3.map(add);Now we have a wrapped curried function, how can we apply it to another wrapped value ? Assume ap (<*> in Haskell) is a function that can apply the function contents of a functor to an wrapped value.
Array.prototype.ap = function(wrappedVal) {
if (this[0] !== undefined) {
return wrappedVal.map(this[0]); //Assuem this[0] is a function
} else {
return [];
}
}
wrappedPlus3.ap(wrapped2);
//=> [5]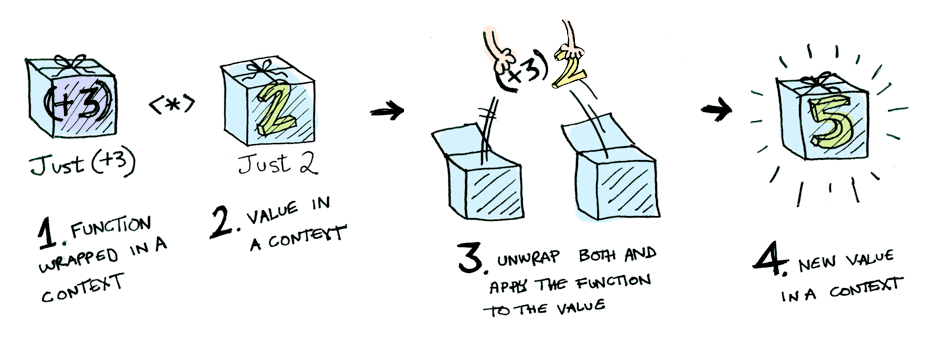
If the we have multiple wrapped functions and values, we might expect this to happen:
Array.prototype.ap = function(wrappedVals) {
var results = [];
for (var i = 0; this.length; i++) {
results.push(wrappedVals.map(this[i])); //this[i] are pure functions without side effects
}
return results;
}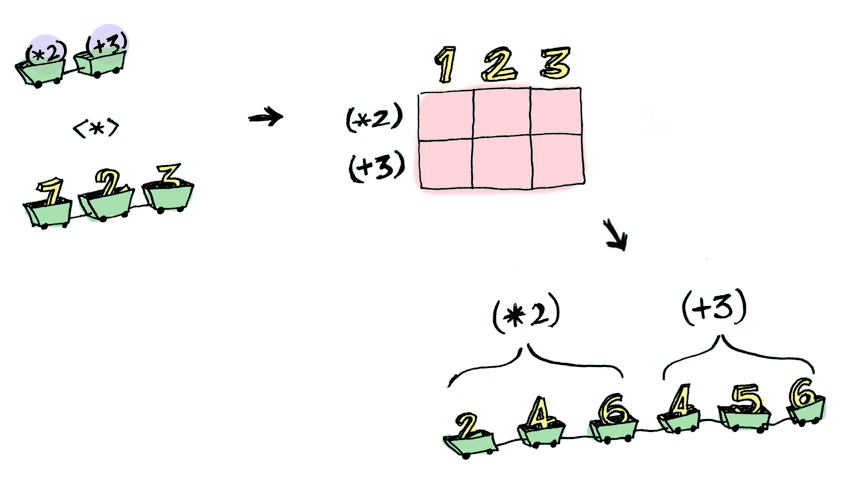
Applicative pushes Functor aside. “Big boys can use functions with any number of arguments,” it says. “Armed with curry function, map (<$> in Haskell) and ap (<*> in Haskell), I can take any function that expects any number of unwrapped values. Then I pass it all wrapped values, and I get a wrapped value out! AHAHAHAHAH!”
How to learn about Monads:
Monads add a new twist.
Functors apply a function to a wrapped value:
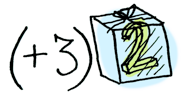
Applicatives apply a wrapped function to a wrapped value:
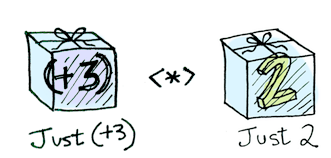
Monads apply a function that returns a wrapped value to a wrapped value.
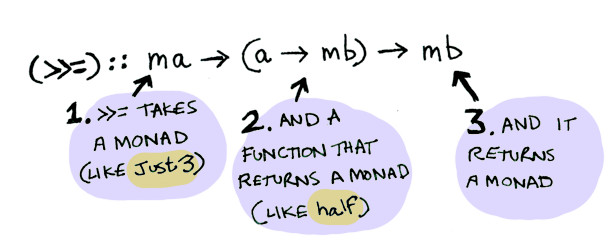
Monads have a function flatMap (liftM in Haskell) (>>= in Haskell pronounced “bind”) to do this.
Array.prototype.flatMap = function(lambda) {
return [].concat.apply([], this.map(lambda));
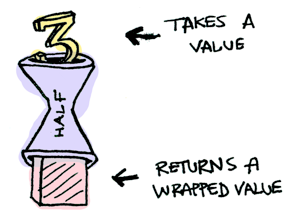
};Suppose half is a function that only works on even numbers:
var half = function(val) {
return val % 2 == 0 ? [val / 2] : [];
}
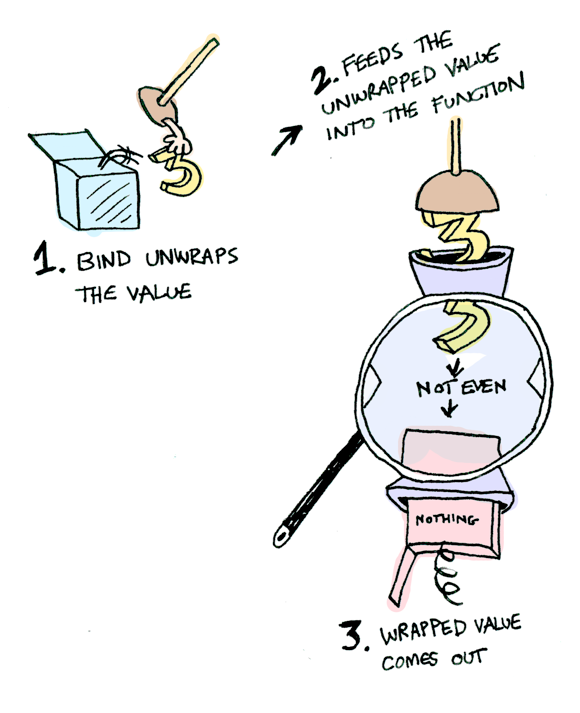
What if we feed it a wrapped value?

We need to use flatMap(>>= in Haskell) to shove our wrapped value into the function.
[3].flatMap(half)
//[]
[4].flatMap(half)
//[2]
[].flatMap(half)
//[]
You can also chain these calls:
[20].flatMap(half).flatMap(half).flatMap(half);
// => []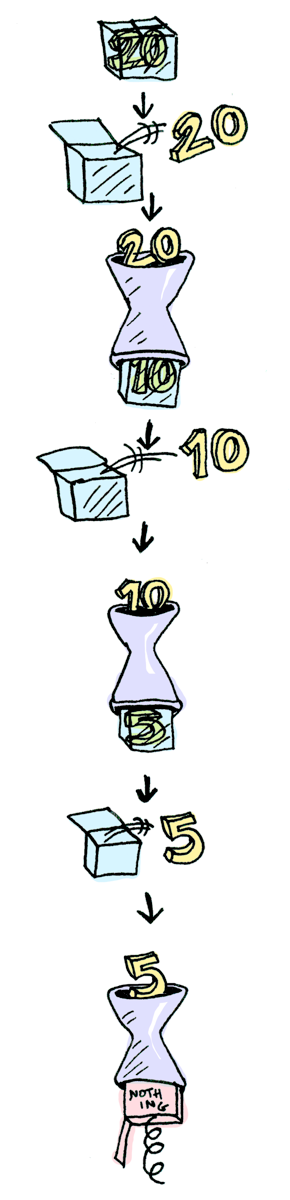
You might have the question that why don’t we just use map. I am glad you ask ! This is because half returns a wrapped value. If we use map, we are putting a container inside another container.
But why do we return a wrapped value in half ? In this case, we use the wrapped value to represent potential empty **** value and prevent the following calls in the chain from being executed if it’s empty. Let’s look at an other example:
Here’s a simple http request utility where we wrap the response in a promise:
function get(url) {
return new Promise(function(resolve, reject) {
var req = new XMLHttpRequest();
req.open('GET', url);
req.onload = function() {
if (req.status == 200) {
resolve(req.response);
}
else {
reject(Error(req.statusText));
}
};
req.onerror = function() {
reject(Error("Something Wrong!"));
};
req.send();
});
}With above utility, we try to make sequential calls to get the info of the first connection of contact 1.
get("https://www.friends.com/contacts/1")
.then(function (result) {
return JSON.parse(result); //Return a value, this can also throw an error
})
.then(function (parsedJSON) {
var contactId = parsedJSON.connections[0];
return get("https://www.friends.com/contacts/" + contactId); //Return a promise
})
.then(function (result) {
return JSON.parse(result);
}, function (err) {
//Handle the error here
console.error(err);
});The onFullfilled lambda can return either a value or a promise (thenable). When it returns a value, then is like a map function. When it returns another promise, then acts like a flatMap. The resolution state of returned promise will control the following operations and yield the eventual value (contact info of the first connection of contact 1.).
So, we can see the following traits:
What is the difference between the three?

So, dear friend (I think we are friends by this point), I think we both agree that monads are easy and a SMART IDEA(tm). Now that you’ve wet your whistle on this guide, why not pull a Mel Gibson and grab the whole bottle. Check out LYAH’s section on Monads. There’s a lot of things I’ve glossed over because Miran does a great job going in-depth with this stuff.
As a javascript programmer, you already more or less use functional programming in your daily work unconsciously !
Even though you might find it’s not too relevant as javascript is not strictly typed, I hope the article gives you a good introduction of functional programming and prepares you to learn other functional languages such as Scala.
A reference of functional programming terms
A pure function is a function that, given the same input, will always return the same output and does not have any observable side effects.
A side effect is a change of system state or observable interaction with the outside world that occurs during the calculation of a result.
You can call a function with fewer arguments than it expects. It returns a function that takes the remaining arguments.
const compose = ( f, g ) => x => f( g( x )); -
take two functions and a value then calls the first function with the
result of the second function that utilises the value as its argument.
The second function g is evaluated first to produce a new
value that is then the argument for the first function f.
Most implementations of compose will allow the use of more than two
functions.
Pointfree functions never mention the data upon which they operate. Example:
const initials = name => name.split( " " ).map( compose( toUpperCase, head, )).join( ". " );
const initialsPointFree = compose( join( ". " ), map( compose( toUppercase, head )), split( " " ));Imperative coding is written as step by step instructions. For
example in a for loop one would set out the parameters of
the loop and then instruct the program what happens per each loop.
Declarative coding is written with expressions. In the previous example
one might simple say something like map( increment ). The
specific implementations of map or increment
aren’t important and can change (providing the changes still follow the
basic idea of mapping and incrementing!).
The system used to describe the type signature of functions. This
allows anyone reading through code to get a sure understanding of what
exactly the function will do without having to read the actual
implementation. E.g.
// match :: Regex -> ( String -> [ String ]) - match
is a function that takes in a regex and returns a function that itself
takes a string and returns an array of strings. Should the function take
an argument of any type then you would use something along the lines of
// id :: a -> a. In this case a is a
variable but the return type must be the same type as a.
Lastly, map has a signature of
// map :: ( a -> b ) -> [ a ] -> [ b ]. Here the
second variable b can be the same as a or
different; map can map from String to String or Number to String for
example.
refers to map (or fmap) whilst<>is ap e.g.add
<$> Right 2 <> Right 3`.A natural transformation is a “morphism between functors” that is to say a function that operates on containers themselves. A key point of these natural transformations is that one cannot see the contents of functors. A secret transaction if you will. In code it looks like so:
// nt :: ( Functor f, Functor g ) => f a -> g a
compose( map( f ), nt ) === compose( nt, map( f ));Moving back and forth between containers is considered an isomorphism, largely meaning “holds the same data”. When two containers can transform “to” and “from” each other they are isomorphic whilst not losing data. An example of a non-isomorphic transformation is thus:
// maybeToArray :: Maybe a -> [ a ]
const maybeToArray = x => ( x.isNothing() ? [] : [ x.$value ]);
// arrayToMaybe :: [ a ] -> Maybe a
const arrayToMaybe = x = Maybe.of( x[ 0 ]);
const x = [ "elvis costello", "the attractions" ];
maybeToArray( arrayToMaybe( x )); // [ "elvis costello" ]A functor is a container-like type that implements map. A functor must obey a few laws:
map( id ) === idcompose( map( f ), map( g )) === map( compose( f, g ))Maybe is a functor that contains a isNothing function
that checks for a non-null or undefined value. Usually, the result of a
function call that utilises Maybe will yield a Just
functor with valid data or Nothing for null data. This
is used to deal with function calls that may, or may not, yield null
values allowing one to map over null values.
Either is another container type that deals with error handling. It
captures logical disjunction, ||, in a type. Either has two
subclasses of Right and Left. Should everything work correctly we get a
Right type functor that does as you would expect. On the other hand, a
Left is returned which has an implementation of map that simply returns
the value held by the container. This allows one to understand why
something failed at a particular point carrying more information than
the Maybe type.
IO is a functor that takes in a function as it’s $value property. IO
is used to store non-pure functions that at some point in time will have
to be run and unleash side-effects and whatnot. Side note: impure
functions can be written purely by storing them in a pure
function e.g. const pure = x => impure( x );. The pure
function will always return the same impure function with the
same output irregardless of the value of x. IO works on similar
lines.
Task is an asynchronous version of IO. It also resembles Promises
replacing .then() with a map call. When ready one calls
.fork() to run the commands of Task which is similar to
unsafePerformIO of IO. Task can also do a similar job of
Either as it has error and success paths like Left & Right
respectively. Either and IO can/will still be used in conjunction with
Task.
A pointed functor is a functor with an of method. This
allows one to place values in what’s called a default minimal
context.
A monad is a functor that is pointed and can flatten. For example,
when composing functions that return functors you may end up with a
chain of nested functions e.g. IO( IO( "pizza" )). A monad
has a join method that flattens two layers of the same
type. Join is often called after map so there
is also a function called chain (or bind,
flatMap) that combines a map &
join. Monads must also, of course, obey rules to be worthy
of the name.
compose( join, map( join )) === compose( join, join );compose( join, of ) === compose( join, map( of )) === id;Applicative Functors allows one to apply functors to each other. The
interface is defined as a pointed functor with an ap
method. As always, applicatives obey laws. Firstly, applicatives are
“closed under composition” meaning they will not change container types
on us.
A.of( id ).ap( v ) === v. Applying id from
within a functor shouldn’t alter the value in v.A.of( f ).ap( A.of( x )) === A.of( f( x )). In essence,
running functions within containers is the same as running them out of
containers.v.ap( A.of( x )) === A.of( f => f( x )).ap( v ). This
law states that it doesn’t matter if we choose to lift our function into
the left or right side of ap.A.of( compose ).ap( u ).ap( v ).ap( w ) === u.ap( v.ap( w )).Applicatives are best used when one has multiple functor arguments. All function calls can stay within containers and reduces the need for monads unless explicitly required.